[머신러닝] Advance day2-2 Plotting with numerical data (이재원 강사님)
Plotting with numerical data
Python으로 plot을 그릴 때 matplotlib을 많이 사용하지만
문법이 복잡하고 arguments 이름이 직관적이지 않아 그릴때마다 메뉴얼을 찾게 되며
반복되는 코드를 작성해야합니다.
Seaborn은 이런점을 개선한 high-level plottin package입니다.
이번 시간에는 Seaborn=0.9.0 의 공식 튜토리얼을 바탕으로 몇가지를 더하여 알아보겠습니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
가장 기본적으로 많이 사용하는 package들을 import해줍니다.
위 코드의 경우 거의 항상 사용하므로 외워두는게 좋습니다.
Seaborn은 Pandas와 잘 맞습니다. Pandas.DataFrame의 plot 함수는 기본적으로 matplotlib을 사용합니다.
seaborn은 DataFrame을 입력받아 plot을 그릴 수 있도록 구현되어있습니다.
Seaborn에서 제공하는 tips 데이터를 통해 몇가지 plot을 그려보겠습니다.
tips = sns.load_dataset("tips")
tips 데이터를 불러옵니다.
Scatter plots
두 변수간의 관계를 살펴보려면 scatter plot이나 line plot을 사용합니다.
우선 scatter plot을 그려보면서 seaborn의 기초분법을 익혀봅니다.
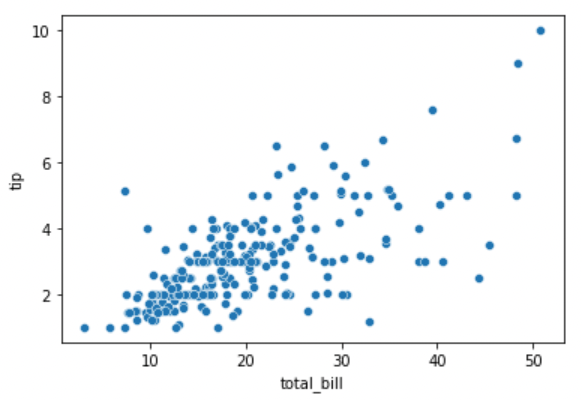
sns.scatterplot(x="total_bill", y="tip", data=tips)
괄호안을 살펴보면 x와 y, data에 대해 정의해주고 있는데 이는 plot이 그려질 때 x축과 y축, 사용될 data를 의미합니다. 위 코드는 아래와 같은 그래프를 그려줍니다.
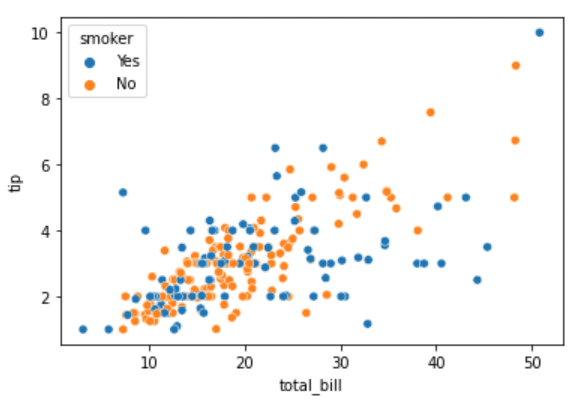
sns.scatterplot(x="total_bill", y="tip", hue="smoker", data=tips)
흡연 유무에 따라 다른 색을 칠하고 싶다면 hue=”smoker” 라는 parameter를 추가해 어떤 변수를 기준으로 다른 색을 칠할지 알려줍니다. 해당 변수가 여러종류로 되어있다면 각각 서로 다른 색이 칠해집니다.
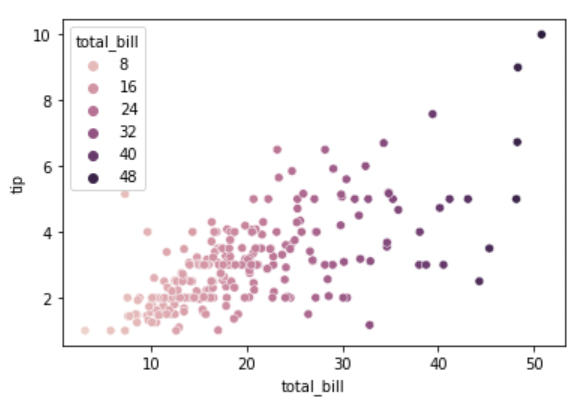
sns.scatterplot(x="total_bill", y="tip", hue="total_bill", data=tips)
hue에 입력되는 값이 명목형이 아닌 실수형이라면 그라데이션 형식으로 색을 칠합니다.
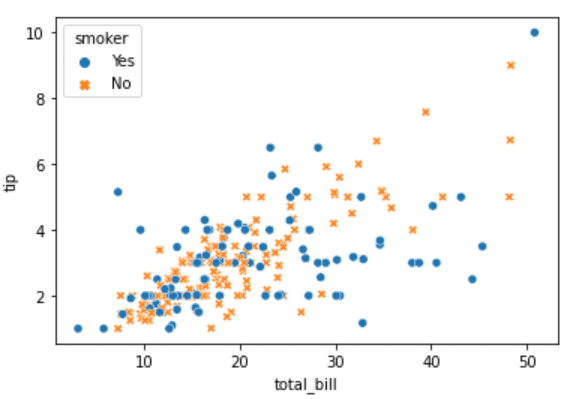
sns.scatterplot(x="total_bill", y="tip", hue="smoker", style="smoker", data=tips)
Marker style을 변경하고 싶다면 style argument를 추가해줍니다.
sns.scatterplot(x="total_bill", y="tip", size="size", data=tips)
marker의 사이즈를 구분하고 싶다면 size argument를 추가해줍니다.
sns.scatterplot(x="total_bill", y="tip", size="size", sizes=(15, 200), data=tips)
sizes 라는 argument를 통해 marker 크기의 상한과 하한도 설정할 수 있습니다.
sns.scatterplot(x="total_bill", y="tip", size="size", sizes=(15, 200), alpha=.3, data=tips)
alpha는 marker의 투명도입니다. 0부터 1사이의 값을 통해 투명도를 조절합니다.
relplot()
seaborn의 relplot()을 사용하면 scatterplot()에서 제공하는 모든 기능을 사용할 수 있습니다.
relplot()은 FacetGrid와 scatterplot()과 lineplot()의 혼합입니다.
kind argument에 기본값을 scatter로, 따로 명시하지 않는다면 scatterplot이 그려집니다.
kind=’line’ 이라고 정의한다면 lineplot이 그려지게됩니다.
sns.relplot(x="total_bill", y="tip", hue="smoker", size="size", sizes=(15, 200), data=tips, kind='scatter')
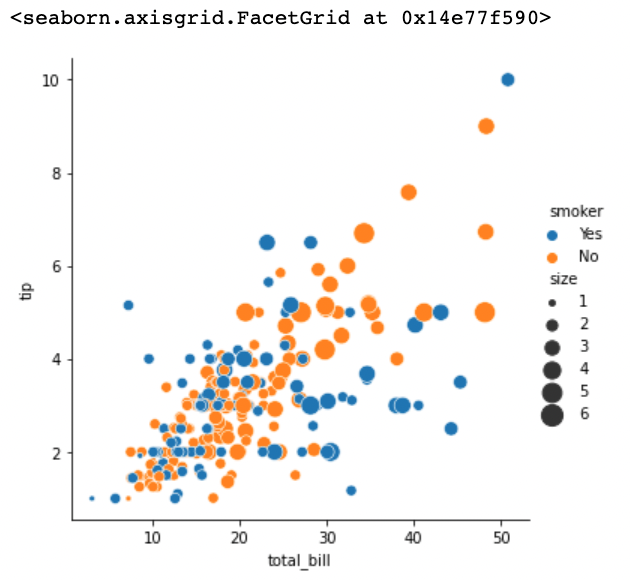
relplot으로 그래프를 그리면
<seaborn.axisgrid.FacetGrid at 0x7f0dfda88278>
이러한 글자가 출력되는데 이는 relplot() 함수가 return하는 변수 설명이며 at 뒤는 메모리 주소입니다.
seaborn.scatterplot() 함수의 return에는 FacetGrid가 아닌 AxesSubplot이 오는 것을 확인할 수 있습니다.(FacetGrid는 1개 이상의 AxesSubplot의 모음)
seaborn.scatterplot()과 seaborn.lineplot()은 각각 한장의 matplotlib Figure를 그리는 것인데 반해, relplot()은 이들의 묶음을 return합니다.
여기서 중요한 점은 이 함수들이 각각 무엇인가를 return한다는 것입니다.
이 return된 변수를 통해 그래프를 수정할 수 있습니다.
아래에서는 return되는 변수들을 g로 받아 확인해보겠습니다.
Utils
title
그래프의 제목을 추가합니다.
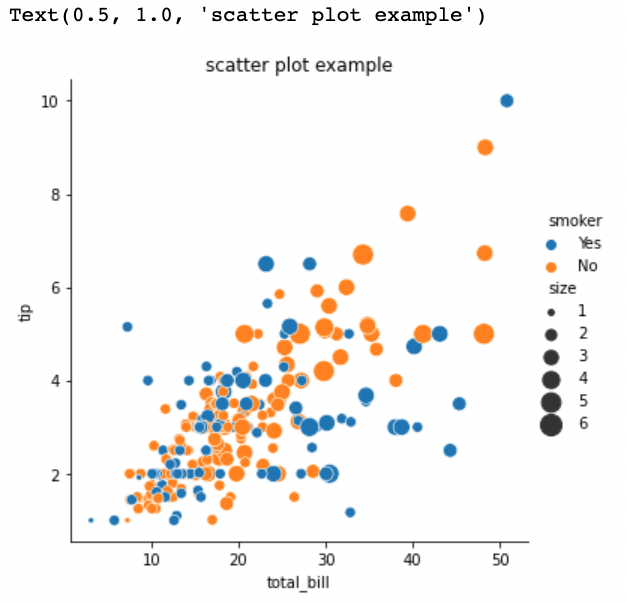
g = sns.relplot(x="total_bill", y="tip", hue="smoker", size="size", sizes=(15, 200), data=tips, kind='scatter')
g = g.set_titles('scatter plot example')
이유는 알 수 없지만 제목이 추가되지 않았습니다. 아래 코드를 통해 제목을 추가합니다.
g = sns.relplot(x="total_bill", y="tip", hue="smoker", size="size", sizes=(15, 200), data=tips, kind='scatter')
plt.title('scatter plot example')
Save
relplot()함수는 실행될 때마다 새로운 그래프를 그리기 때문에, 추가작업을 하려면 이들을 변수에 저장해야합니다. 각 그래프를 변수에 담은 뒤 savefig 함수를 통해 저장합니다.
g0 = sns.relplot(x="total_bill", y="tip", hue="smoker", size="size", data=tips, kind='scatter')
g1 = sns.relplot(x="total_bill", y="tip", size="size", sizes=(15, 200), data=tips)
g0.savefig('total_bill_tip_various_color_by_size.png')
g1.savefig('total_bill_tip_various_size_by_size.png')
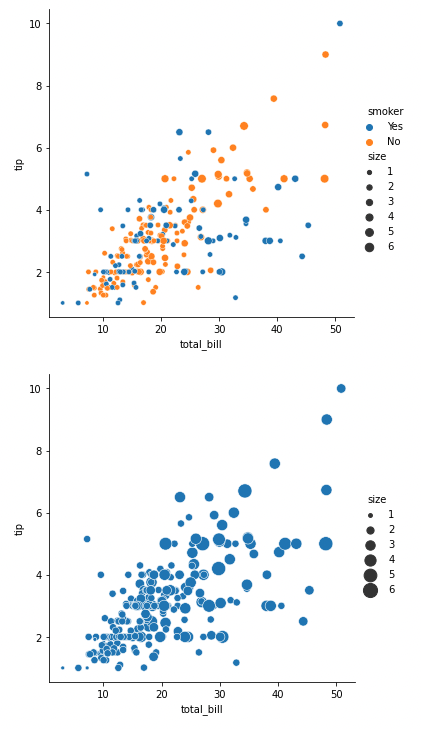
참고로 FacetGrid는 savefig 를 제공하지만 AxesSubplot은 제공하지 않습니다.
물론 matplotlib.pyplot.savefig() 나 get_figure().savefig() 함수를 이용하면 되지만, 코드가 길어지므로 scatterplot()보다는 relplot()을 이용하는 것이 덜 수고스럽습니다.
Pandas.DataFrame.plot
g = tips.plot(x='total_bill', y='tip', kind='scatter', title='pandas plot example')
g = g.get_figure()
g.savefig('pandas_plot_example.png')
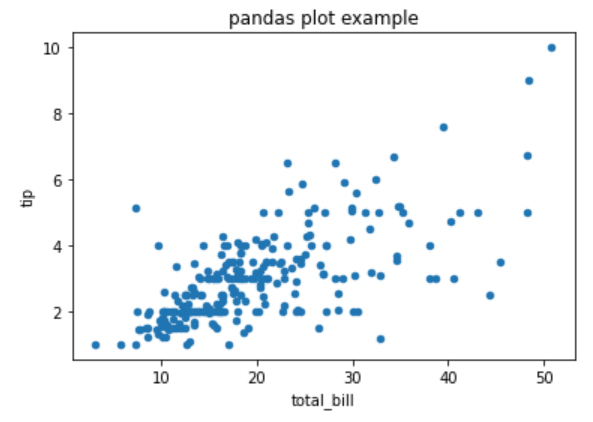
Pandas의 DataFrame을 통해 그래프를 그렸을 경우 return type은 Figure가 아닌 AxesSubplot입니다.
이를 저장하고자 한다면 AxesSubplot.get_figure()를 통해 Figure를 만든 뒤, savefig()를 통해 저장할 수 있습니다.
혹은 아래와 같이 matplotlib.pyplot.savefig 를 이용하여 AxesSubplot 상태에서 바로 저장할 수도 있습니다.
ax = tips.plot(x='total_bill', y='tip', kind='scatter', title='pandas plot example')
plt.savefig('pandas_plot_example_2.png')
matplot.pyplot.close()
Matplotlib 은 현재의 Figure 가 명시적으로 닫히지 않으면 계속 그 Figure 위에 그림을 덧그리는 형식이기 때문에 새로운 그래프를 그리기 전에는 항상 matplotlib.pyplot.close() 함수를 실행시켜야합니다.
data = {
'x': np.random.random_sample(100) * 50,
'y': np.random.random_sample(100) * 10
}
random_noise_df = pd.DataFrame(data, columns=['x', 'y'])
random_noise_df.head(5)
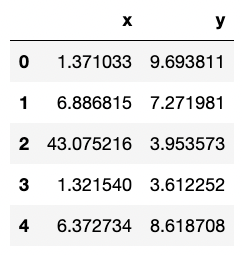
random noise data를 하나 생성했습니다.
이 상태로 각각의 data를 seaborn.scatterplot()에 넣으면
g0 = sns.scatterplot(x="total_bill", y="tip", hue='smoker', alpha=0.8, size="size", sizes=(15, 200), data=tips)
g1 = sns.scatterplot(x="x", y="y", alpha=0.2, color='g', data=random_noise_df)
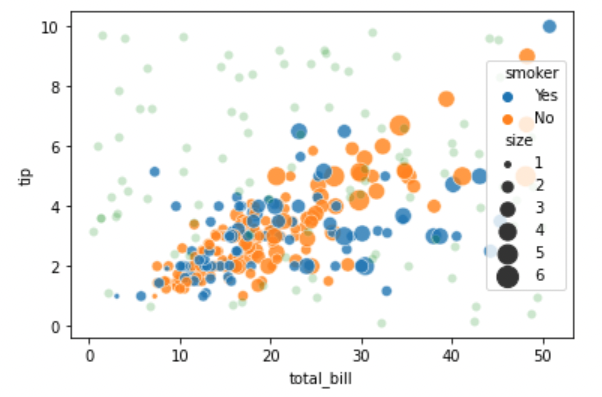
위와 같이 그래프가 겹쳐져서 그려집니다.
실제로 g0와 g1의 메모리 주소 또한 같습니다.
g0, g1

g0 = sns.scatterplot(x="total_bill", y="tip", hue='smoker', alpha=0.8, size="size", sizes=(15, 200), data=tips)
plt.close()
g1 = sns.scatterplot(x="x", y="y", alpha=0.2, color='g', data=random_noise_df)
따라서 위와 같이 plt.close() 로 기존에 그려지고 있던 Figure를 닫아줍니다.
그런 다음 메모리 주소를 찍어보면

위와 같이 서로 다른 메모리 주소를 가지게 된 것을 알 수 있습니다.
아래 그래프는 Figure가 정상적으로 구분 된 뒤의 결과물입니다.
g0 = sns.scatterplot(x="total_bill", y="tip", hue='smoker', alpha=0.8, size="size", sizes=(15, 200), data=tips)
g1 = sns.relplot(x="x", y="y", alpha=0.2, color='g', data=random_noise_df)
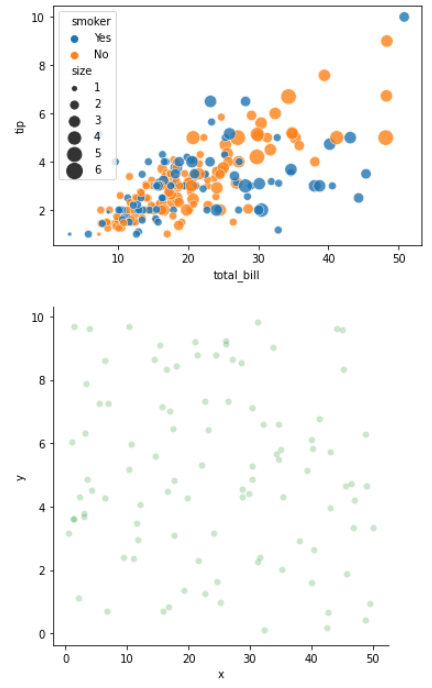
Plotting with numerical data2
Line plots
데이터가 순차적 형식이라면 line plot을 통해 데이터의 경향을 파악할 수 있습니다.
임의의 시계열 데이터를 만들어 lineplot을 그려봅니다.
자연스러운 순차적 흐름을 가진 데이터를 만들려면 cumsum() 함수를 통해 지금까지의 모든 값을 누적할 수 있습니다.
data = {
'time': np.arange(500),
'value': np.random.randn(500).cumsum()
}
df = pd.DataFrame(data)
df.head(5)
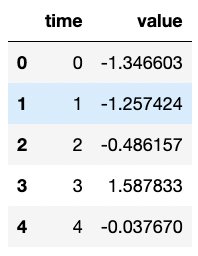
임의의 시계열 데이터 생성
g = sns.relplot(x="time", y="value", kind="line", data=df)
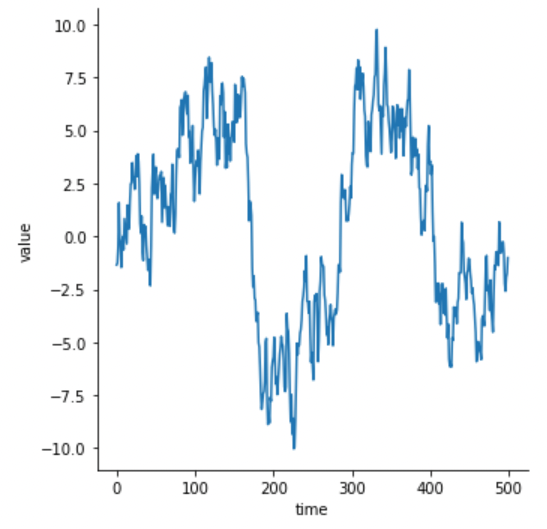
x축을 중심으로 데이터가 잘 정렬되어있다면 위와 같은 그래프가 그려집니다.
하지만 정렬되지 않은 데이터의 경우 아래와 같은 그래프가 그려질 수 있습니다.
# 정렬되지 않은 데이터셋
data = np.random.randn(500, 2).cumsum(axis=0)
df = pd.DataFrame(data, columns=["x", "y"])
df.head(5)
g = sns.relplot(x="x", y="y", sort=False, kind="line", data=df)
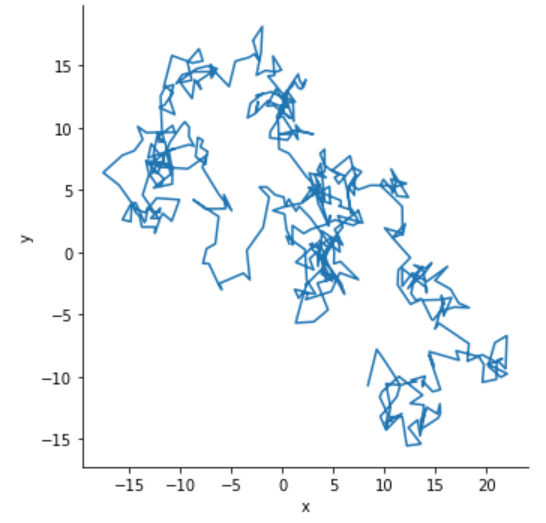
기본적으로 시계열 형식의 데이터는 원활한 plotting을 위해 sort 의 기본값이 True로 설정되어있습니다.
sns.relplot(x="x", y="y", sort=True, kind="line", data=df)
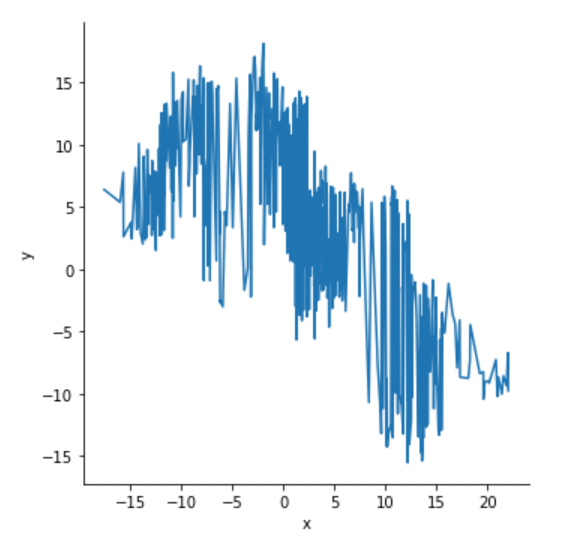
Aggregation and representing uncertainty
seaborn.lineplot()은 신뢰구간(confidence interval)과 추정회귀선(estminated line)을 손쉽게 그려준다는 장점이 있습니다.
seaborn에서 제공하는 기본 데이터셋인 fMRI를 통해 알아보겠습니다.
(fMRI는 각 사람의 활동에 따라 시점별로 측정한 값을 정리한 시계열 데이터입니다.)
fmri = sns.load_dataset("fmri")
fmri.head(5)
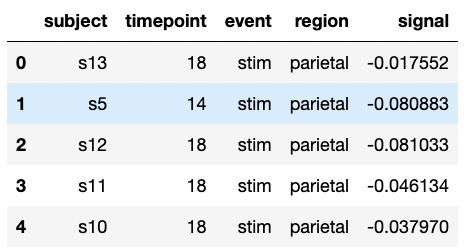
g = sns.relplot(x="timepoint", y="signal", kind="line", data=fmri)
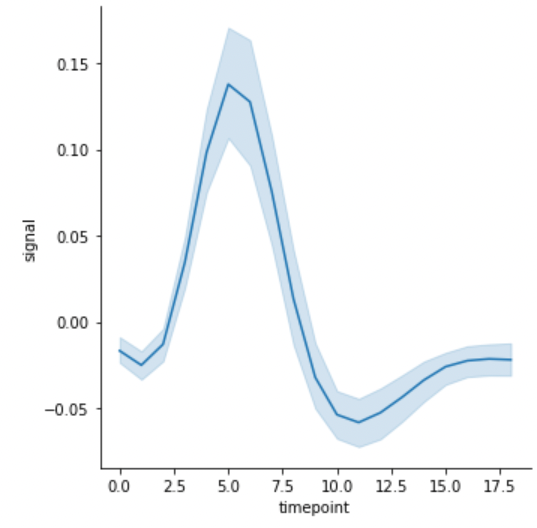
lineplot()은 기본적으로 신뢰구간과 추정회귀선을 함께 그려줍니다.
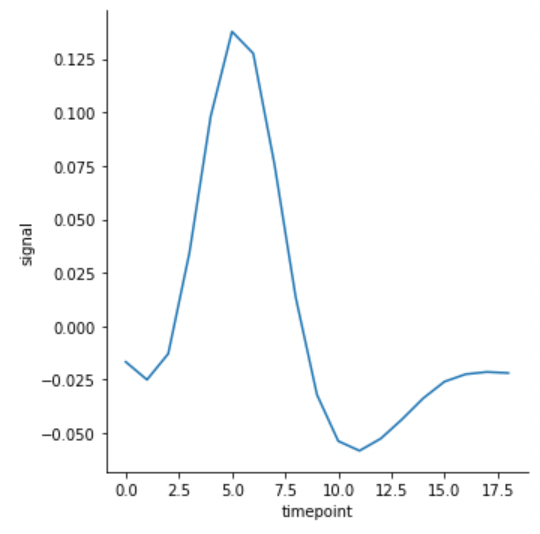
신뢰구간을 제거하고 싶다면 ci=None 을 추가해줍니다.
ci 는 confidence interval 의 약자입니다.
g = sns.relplot(x="timepoint", y="signal", kind="line", data=fmri, ci=None)
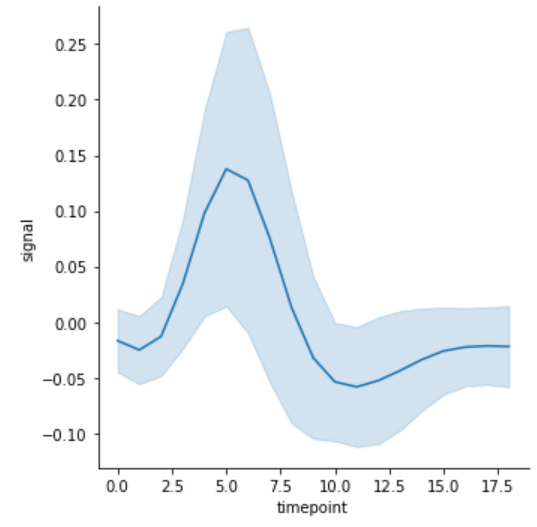
데이터의 표준편차를 confidence interval로 그릴 수도 있습니다.
g = sns.relplot(x="timepoint", y="signal", kind="line", data=fmri, ci="sd")
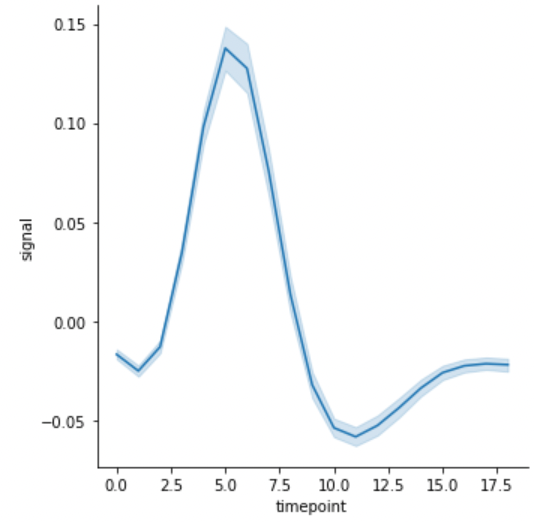
또는 bootstrap sampling (복원 반복 추출) 을 이용하여 50 % 의 값을 confidence interval 로 이용할 경우에는 ci=50을 입력합니다. 이 때 boostrap sampling 의 개수도 n_boot에서 설정할 수 있습니다.
g = sns.relplot(x="timepoint", y="signal", kind="line", data=fmri, ci=50, n_boot=5000)
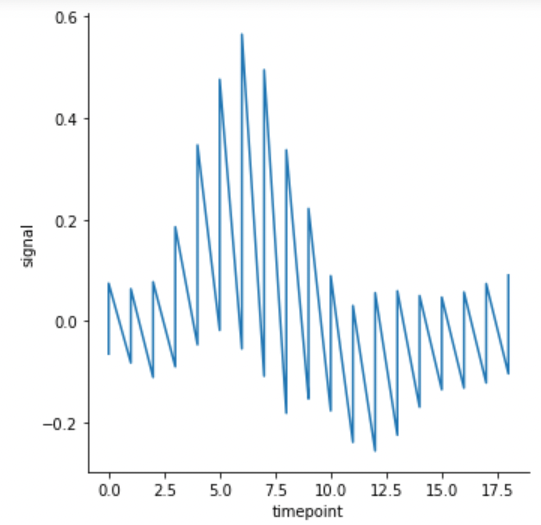
추정 회귀선을 제거하고 싶다면 estimator를 None 으로 설정하면됩니다.
기본 추정 방법은 x 를 기준으로 moving windowing 을 하는 것입니다.
추정선이 없다보니 주파수처럼 signal 값이 요동치는 모습을 볼 수 있습니다.
g = sns.relplot(x="timepoint", y="signal", kind="line", data=fmri, estimator=None)
Add conditions to line plot
lineplot() 또한 scatterplot()처럼 hue와 style을 설정할 수 있습니다.
g = sns.relplot(x="timepoint", y="signal", hue="event", style="event", kind="line", data=fmri)
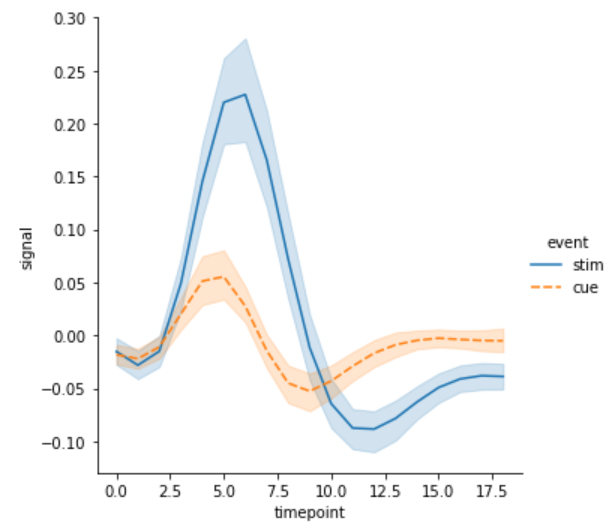
g = sns.relplot(x=”timepoint”, y=”signal”, hue=”event”, style=”event”, kind=”line”, data=fmri)hue와 style을 다른 기준으로 정의하거나, 선 중간에 x 의 밀도에 따라 marker 를 입력할 수도 있습니다.
g = sns.relplot(x="timepoint", y="signal", hue="region", style="event",
markers=True, kind="line", data=fmri)
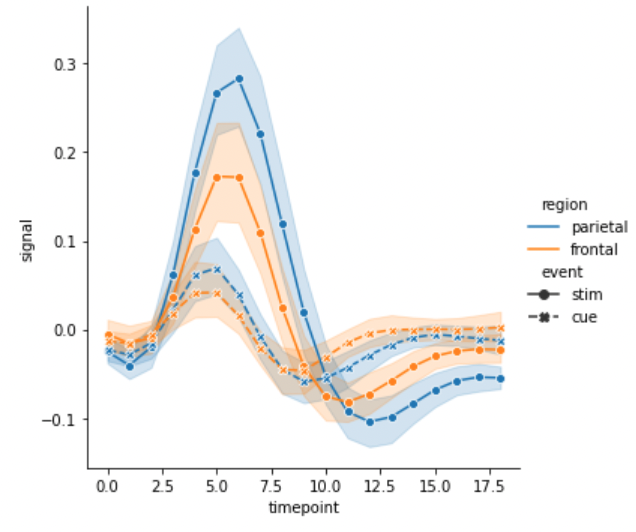
선의 색은 ‘region’ 에 따라 구분하지만, 각 선은 ‘subject’ 를 기준으로 중복으로 그릴 경우 units에 ‘subject’ 를 입력합니다. 만약 units을 설정하면 이때는 반드시 estimator=None으로 설정해야 합니다. 여러 개의 ‘subject’ 가 존재하다보니 선이 지저분하게 겹칩니다.
g = sns.relplot(x="timepoint", y="signal", hue="region",
units="subject", estimator=None, kind="line",
data=fmri.query("event == 'stim'"))
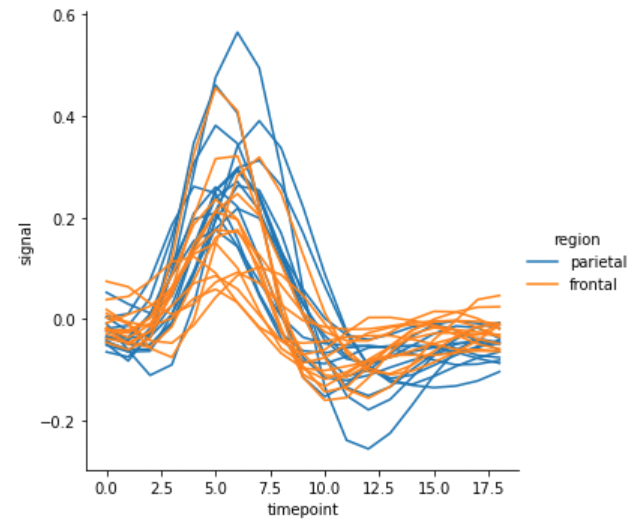
Plottin with date data
시계열 데이터 중에는 x축이 날짜 형식이 데이터가 있습니다.
data = {
'time': pd.date_range("2017-1-1", periods=500),
'value': np.random.randn(500).cumsum()
}
df = pd.DataFrame(data)
df.head(5)
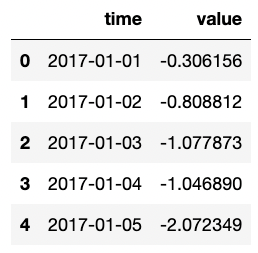
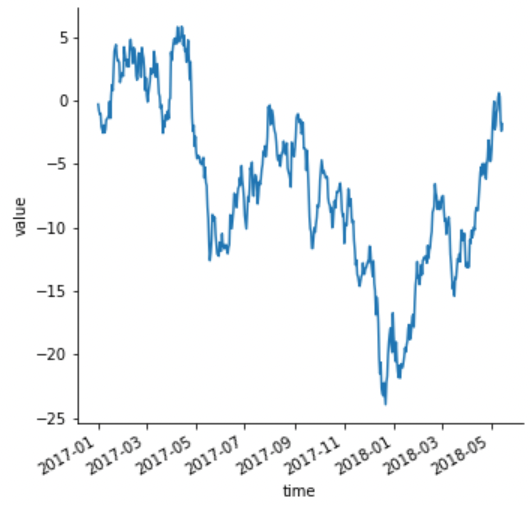
이 데이터로 lineplot을 그립니다. 이 때 autofmt_xdate()함수를 이용하면 x 축의 날짜가 서로 겹치지 않게 정리를 도와줍니다.
g = sns.relplot(x="time", y="value", kind="line", data=df)
g.fig.autofmt_xdate()
multiple plots
앞서 seaborn.scatterplot()과 seaborn.relplot()의 return type 이 각각 AxesSubplot
과 FacetGrid로 서로 다름을 살펴보았습니다. seaborn.relplot()의 장점은 여러 장의 plots 을 손쉽게 그린다는 점입니다. 각 ‘subject’ 별로 line plot 을 그려봅니다. 이때는 col 을 ‘subject’ 로 설정한 뒤, col 의 최대 개수를 col_wrap에 설정합니다. ‘subject’ 의 개수가 이보다 많으면 다음 row 에 이를 추가합니다. 몇 가지 유용한 attributes 도 함께 설정합니다. aspect 는 각 subplot 의 세로 대비 가로의 비율입니다. 세로:가로가 4:3 인 subplots 이 그려집니다. 그리고 세로의 크기는 height로 설정할 수 있습니다.
g = sns.relplot(x="timepoint", y="signal", hue="event", style="event",
col="subject", col_wrap=5, height=3, aspect=.75, linewidth=2.5,
kind="line", data=fmri.query("region == 'frontal'"))
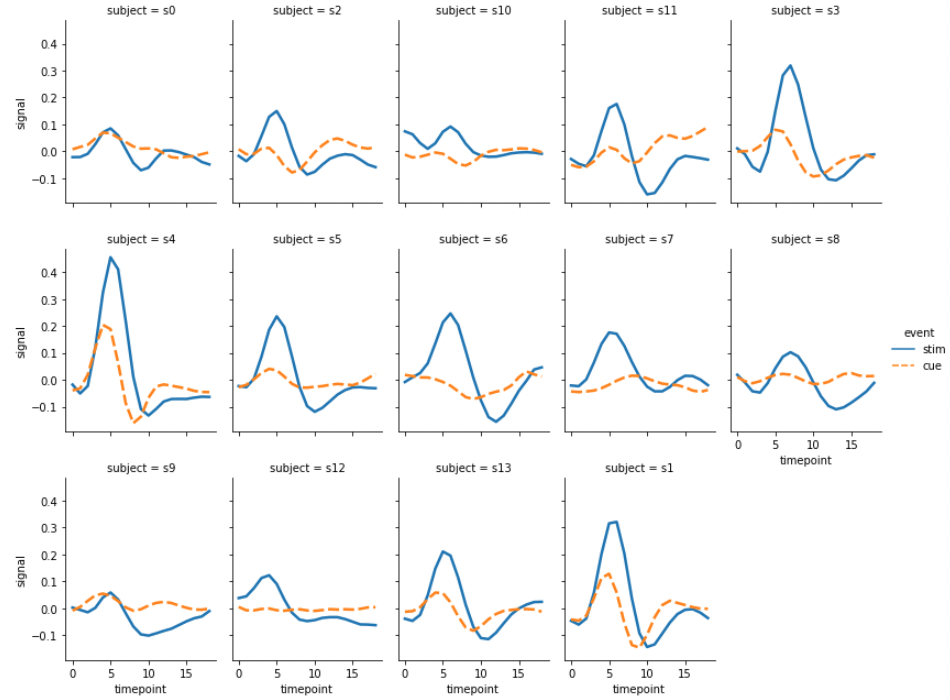
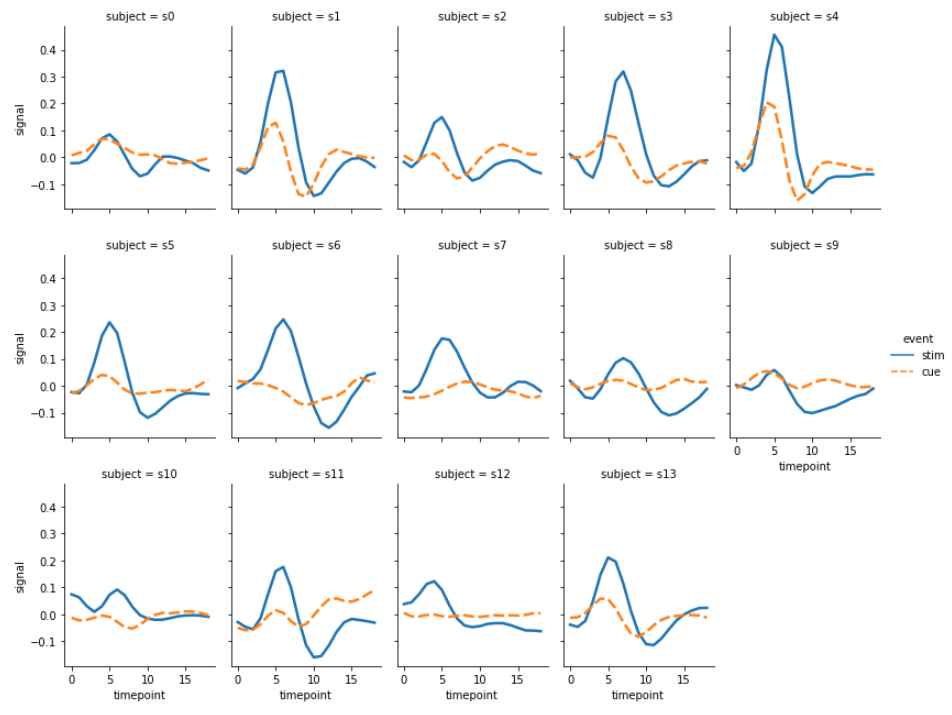
그런데 위의 그림에서 col의 값이 정렬된 순서가 아닙니다. 순서를 정의하지 않으면 데이터에 등장한 순서대로 이 값이 그려집니다. 이때는 사용자가 col_order에 원하는 값을 지정하여 입력할 수 있습니다. row역시 row_order를 제공하니, row단위로 subplots 을 그릴 때는 이를 이용하면 됩니다.
col_order = [f's{i}' for i in range(14)]
g = sns.relplot(x="timepoint", y="signal", hue="event", style="event",
col="subject", col_wrap=5, height=3, aspect=.75, linewidth=2.5,
kind="line", data=fmri.query("region == 'frontal'"),
col_order=col_order
)
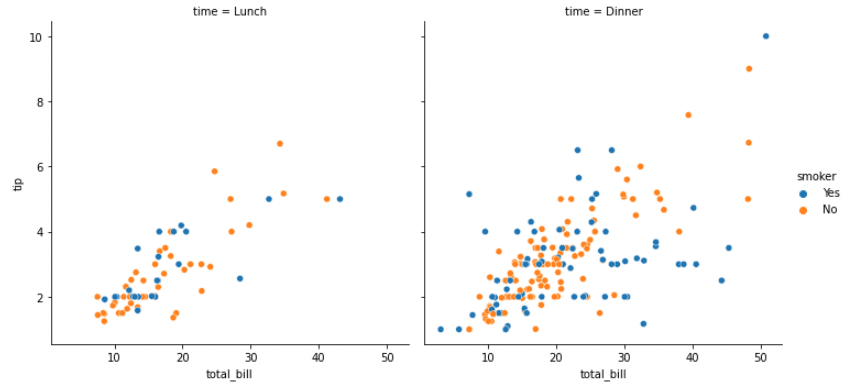
이는 scatter plot 에도 적용할 수 있습니다. 예를 들어 column 은 변수 ‘time’ 에 따라 서로 다르게 scatter plot 을 그릴 경우, 다음처럼 col에 ‘time’ 을 입력합니다. hue, size와 같은 설정은 공통으로 적용됩니다.
g = sns.relplot(x="total_bill", y="tip", hue="smoker", data=tips, col="time")
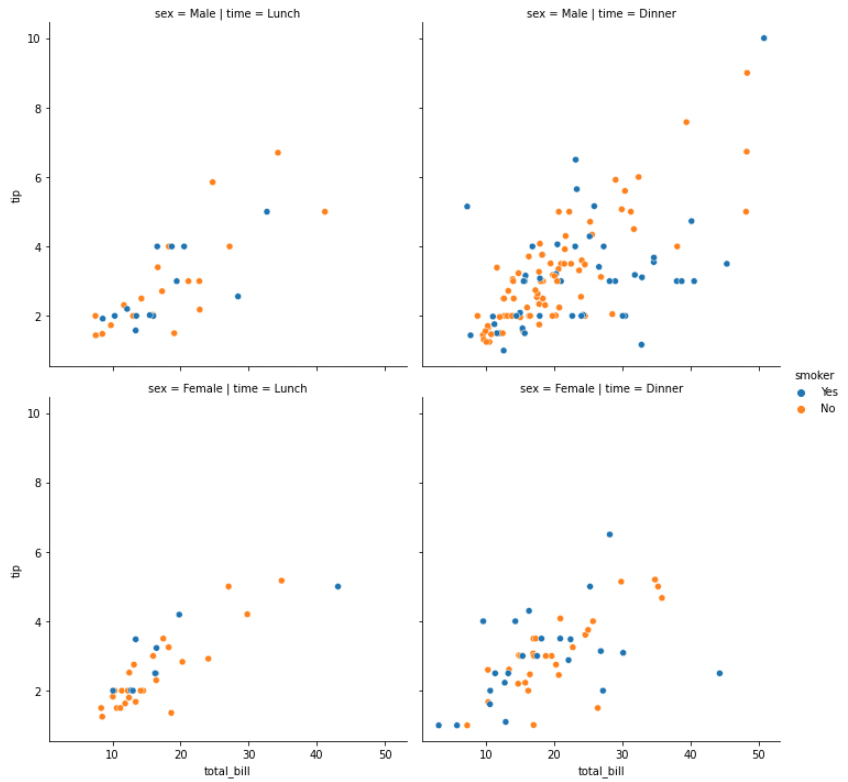
row를 성별 기준으로 정의하면 (2,2) 형식의 grid plot 이 그려집니다.
g = sns.relplot(x="total_bill", y="tip", hue="smoker", data=tips, col="time", row="sex")
댓글남기기