[머신러닝] 기초 개념 day2 (김용담 강사님)
머신러닝 (Machine Learning)
머신러닝 예시 : 학습(training)
기계는 문제를 풀 때 틀려야 학습을 할 수 있음
틀린 문제가 없으면 학습하게 아님
- feed-forward(inference) : 문제를 품
- loss update(learning) : 오답정리
T : 2지선다(classification)
P : Accuracy(맞은 개수의 비율)
컴퓨터는 오답정리할때만 학습이 된다
머신러닝 예시 : 테스트(test, inference)
학습이 완료된 모델을 기준으로 넣는게 아니라 처음보는(새로운) 데이터를 집어넣는다
컴퓨터에게 문제를 풀기만 하는것은 남지 않는다 → 오답정리를 한 문제가 아니라면 매번 처음보는 문제임
unseen data를 풀어서 맞으면 학습이 잘 되었다고 가정
→ labeled dataset
→ 지도학습
맞춘데이터로는 ‘아 이렇게 해서 맞았구나’ 라는 결과를 얻을 수 있음
오답정리를 했다는 기준 → loss update
라벨 : 정답
컴퓨터가 해야하는것 → 라벨을 찾는 것
지도학습(Supervised Learning) → 정답을 알려주고 방향을 제시해줌
머신러닝의 종류
Task of Machine Learning
-
Supervised Learning : 학습 시 사용하는 데이터(x)가 예측 대상(y)을 포함하고 있고, (x,y)의 pair를 학습에 사용하는 방법.
정답정보를 알고있고 학습에 사용
-
Unsupervised learning : 학습 시 사용하는 데이터만을 이용해서 학습하는 방법.
x만 씀(y가 없음) → 뭘 맞춰야 되는지를 모르는 상황
학습의 난이도가 높고
클러스터링을 많이 하다보면
지식이란 무엇인가 라는 생각을 많이 하게됨
비지도학습 : 평가 기준이 있지만 애매한 것
라벨이란 무엇인가
비지도학습은 현업에서 인기가 없음…
y가 있냐 없냐 보다도 학습에 y를 썼냐 안썼냐가 더 중요함
-
강화학습 → 우리 과정에 없는 내용 (컨셉만 이해하고 넘어가자)
최적화 이론에서 출발, 1930년부터 시작
agent, environment
특정 environment에서 agent가 할 수 있는 액션을 주고
environment는 액션에 대한 리액션을 함
environment에 대해서 agent가 해야하는 일
예를들어 자율주행을 하여 기준 시간보다 단축된 기록을 보이면 reward를 제공하고
반대라면 panalty를 주어
사람의 학습과 닮아있고 액션에 대한 결과의 총합으로 최종 리워드를 보고
점점 더 리워드가 높아지는 방향으로 지금까지 한 액션들을 강화하는
환경과 에이전트가 인터랙션하는 구조
그리고 그 리액션에 대해 판단할 수 있는 것
환경 변화(action)에 따른 반응(reaction)
사람의 학습과 가장 닮아있고
테스트가 어렵고 엄청나게 많은 수학적인 부분이 등장 → 최적화 이론과 맞닿아있음
난이도가 높음
강화학습도 T와 P의 개념이 쓰임
강화학습 안에서도 지도학습과 비지도학습이 있고
task를 어떻게 정의하냐에 따라 목표가 다르고
P는 reward를 최대화 하는걸 목표로 두는데
이 reward를 뭘로 정의하냐에 따라 다르고
알파고가 강화학습을 썼다고 하는데
초창기엔 강화학습+지도학습 모델
알파고 제로 모델은 강화학습+비지도학습 모델 (자가학습 → 자기 자신과 바둑을 계속 두어서 실력을 향상시킴)
딥러닝은 머신러닝 방법론 중 하나
뉴럴네트워크를 사용하는
어떤 모델을 쓰느냐
머신러닝의 하위
현재 가장 쓸모가 많아서..
현업에서 정의하는 대부분의 머신러닝 문제들은 지도학습
딥러닝을 쓰냐 안쓰냐 지도학습을 하냐 안하냐
→ 용어상으로는 서비스상에서 내가 무엇을 하는지에 따라
어떤 task를 할건지, 어떤 방법론을 적용할건지를 정해야 하는데
unsupervised learning, supervised learning, reinforce learning → 어떤 머신러닝 task를 할건지
딥러닝 → 어떤 방법론을 쓸건지
## 머신러닝으로 할 수 있는 일들
### Classification(분류), Regression(회귀), ### Anomaly Detection
99퍼센트가 분류나 회귀
### 머신러닝 필수 개념에 대해 알아봅시다
지금부터 언급되는 머신러닝은 딥러닝을 제외한 방법론
일반적으로 “인공지능 기술을 사용하여” 라는 말이 나왔다면 거의 딥러닝
일반적으로 사용하는 용어와 학술적인 용어가 조금 다르다
우리가 배우는 머신러닝 기초 내용도 딥러닝을 제외한 내용
다시말해 머신러닝 방법론에서의 Feature Engineering이 중요함
우리가 Feature Vector를 만든다는 과정에서의 Feature Engineering은
Data를 어떻게 표현할 것인가에 대한 결론임
이번에는 비정형 데이터인 이미지와 텍스트를 다뤄봄
## Feature Vector
### 데이터를 어떻게 표현할 것인가?
- 데이터의 특징을 벡터로 나타낸 것 (정의)
- 어떤 feature를 사용하는지가 굉장히 중요합니다.
- feature engineering
- feature vector가 존재하는 공간을 feature
## Image Feature Vector
### 이미지를 벡터로 나타낸다면?
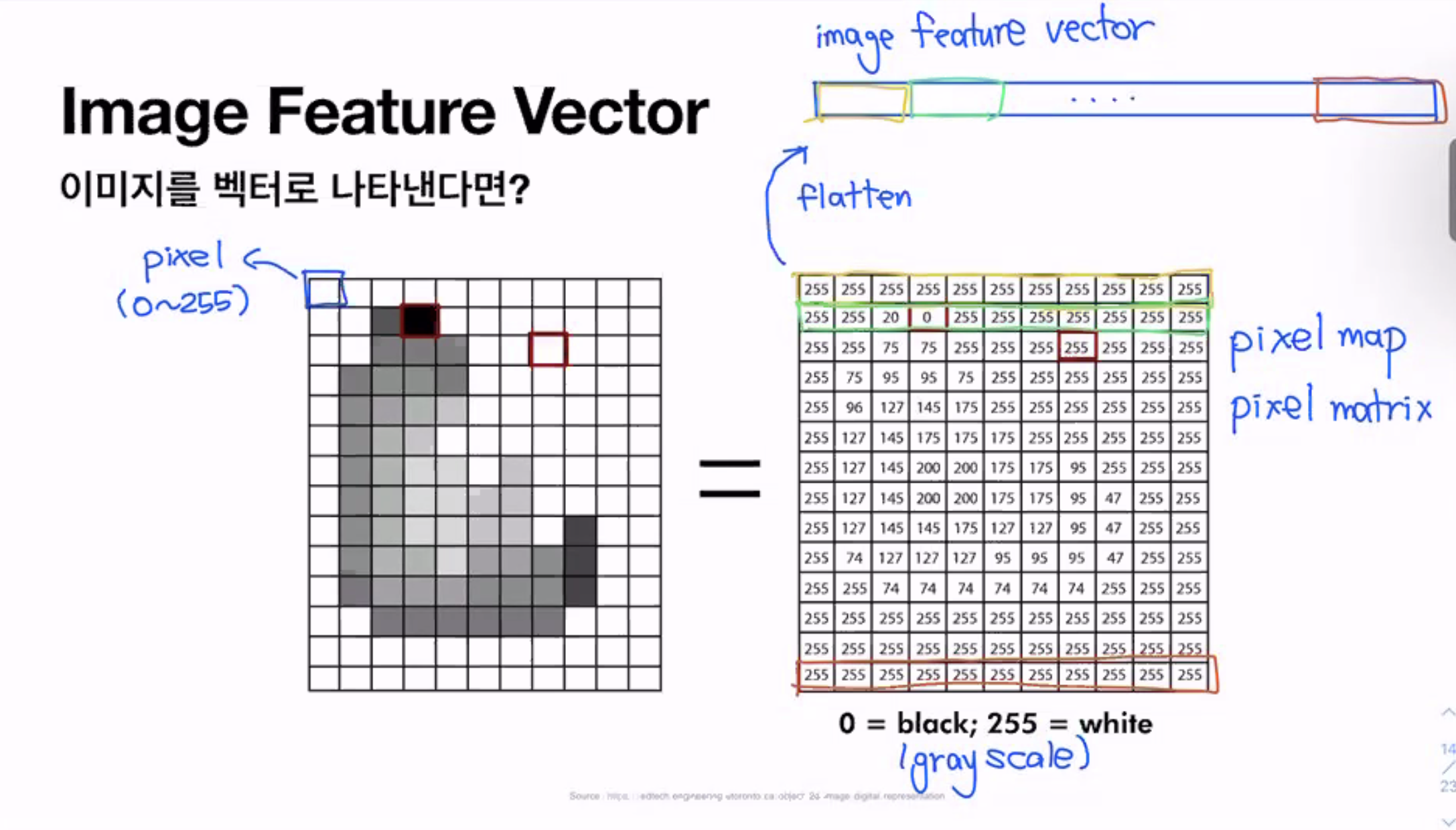
vector들을 쌓아놓은 것이 matrix
→ matrix를 vector로 만드는게 굉장히 중요함
다양한 방법으로 줄일 수 있는데 가장 많이 사용하는 방법은 일자로 펴는것
일자로 펴는 작업 → flatten
펼쳐진 데이터 → image feature vector
이미지를 펼치기만 하고 그냥 사용하면 문제가 되는 점이 있는데 차원이 너무 커짐
그래서 펼친 다음 뭔가를 더함 → 딥러닝 computer vision에서 다룸
기존 머신러닝 기법들을 통해 차원을 줄임
예전에는 image feature vector를 사람이 처리했지만 이제는 컴퓨터가 더 잘 처리함
→ embedding
embedding을 하면 우리가 원하는 차원으로 줄일 수 있음
## Text Feature Vector
### 텍스트를 벡터로 나타낸다면?
Vector Space Model → NNLM(Neural Network Language Model) → word2vec
단어간의 관계를 벡터 연산으로 할 수 있다
말도 안되는 수치연산이 결과적으로 관계를 가짐
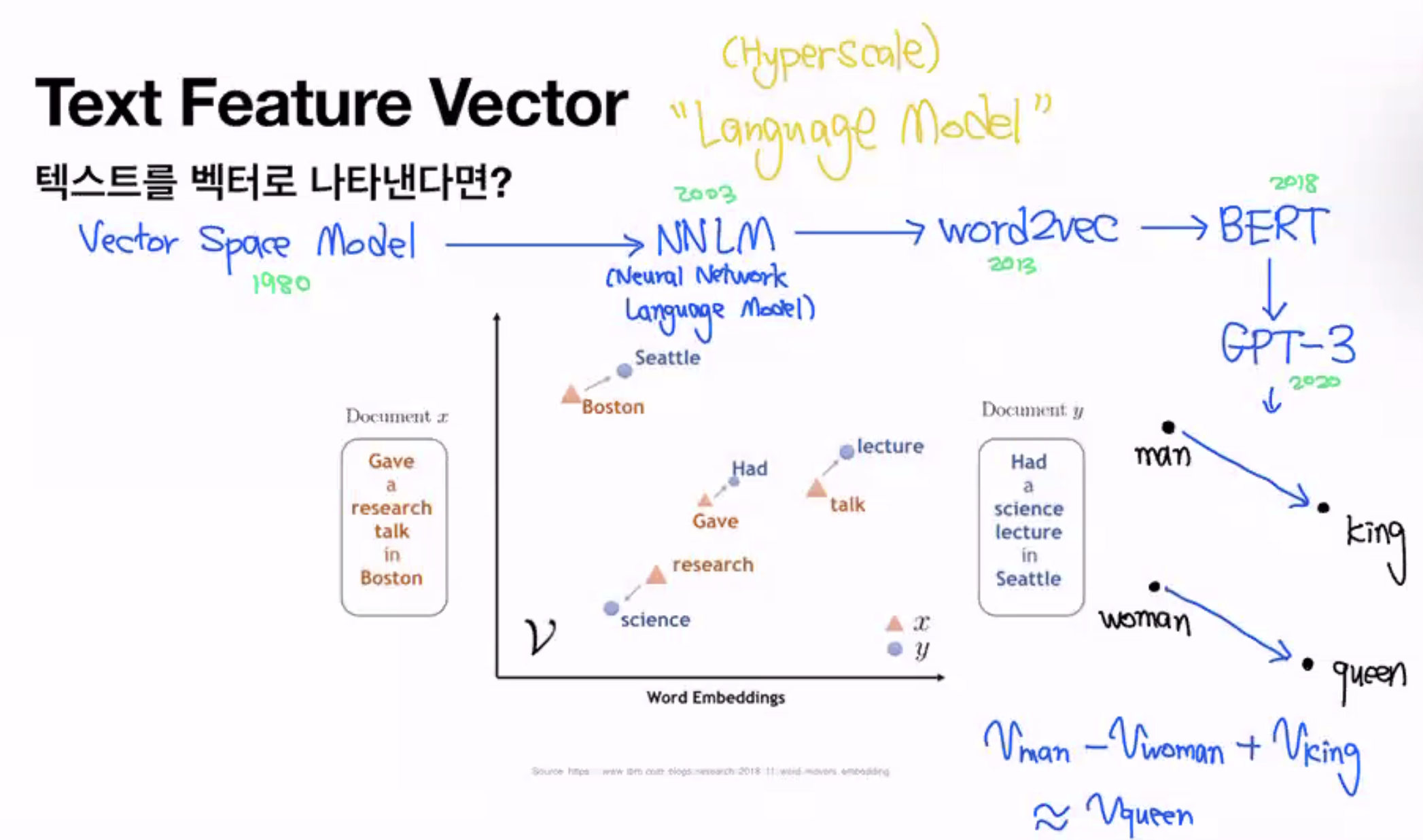
word2vec → 단어를 저차원 vector로 표현했더니 관계를 표현할 수 있게됨
→ 단어간의 관계를 vector를 통해서 표현할 수 있다현재 AI에서 가장 중요한 컨셉 → (Hyperscale) Language Model
## Data Split
### 학습에 필요한 데이터
- 학습에 사용하는 데이터 : training data (PTraining)
- hyperparameter tuning에 사용하는 데이터 : validation data (PVal)
열심히 하는데 validation 성능이 올라가지 않는다 → 지금의 학습방법으로는 어느정도 한계에 다다른것 → 새로운 학습방법을 찾는것 → hyperparameter tuning(학습전략수정)
- 최종 성능확인에 사용하는 데이터 : test data (PTest) : KPI
“prediction for unseen data”
→예측성능 !

PVal의 확인은 학습할때마다 다름(평가 하고싶을 때마다 할 수 있음)
Validation 결과를 오답노트 하는 순간부터 Validation Data는 Training Data가 됨
1회독을 할 때마다 PTraining에 대한 성능은 올라가는데 PVal에 대한 성능은 떨어지는 경우 → Overfitting(과적합)
데이터가 너무 적거나 모델이 너무 복잡하거나 : 정답을 외운 케이스
우리의 목표는 PTest, PVal(학습하지 않은 데이터에 대한 성능-예측)이 올라가는것이기 때문에 PTraining이 올라가는건 중요하지 않음
전체 데이터를 비율로 나눈 이유는
오답정리가 잘 되어야 하므로 training에 비중을 둔다
training이 떨어지고 있다면 Underfitting → 망한거 → 모델을 바꿔야함
- 데이터가 많다? → val과 test의 비율이 적어도 충분한 양이 보장되므로 비율을 줄이는 편
- 데이터가 적다? → 답을 외움 → val과 test의 비율을 늘리는 편
Data Split은 지도학습에만 적용됨
## Loss Function
굉장히 중요한 개념이지만 지금은 온전히 이해하기 힘들 수 있음
모델을 실제 학습 시켜봐야 이해할 수 있음
오늘은 컨셉만 이해하기
통계학에서 데이터 분석을 할 때
이 모델이 얼마나 학습을 잘했는지 → 내가 예측한 값과 실제 정답의 차이를 error
→ 머신러닝에서는 Loss Function이라고 함performance measure가 향상되는 방향으로 학습을 함
→ 컴퓨터에게 시키려면 방향을 줘야함
→ 여기서 방향은 진짜 수학적인 얘기임
→ 어떻게 오답정리를 해야 학습이 잘될지
→ Loss를 함수로써 정의함
→ Optimization
학습의 목적은 무엇인가?
- Loss Function = Target Function
- Loss(error) = y-y^
Loss를 함수로써 정의하면 Optimization 할 수 있음
y → target value (정답)
y^ → predicted value
- →차이
보통은 절대값을 씌우거나 제곱을 함
- Q1. Loss가 0이 되면 어떤 의미일까요?
- A1. y = y^
→ 정답과 예측값이 같은 것

L → w에 대한 함수
실제 Loss가 0이 되는(최소가 되는) 값이 차원에 따라 많을 수 있음
→ w가 복잡해짐
내가 찾고자 하는 함수의 최소값이 바로 나오느 거라면 편하겠지만
우리가 사용하는 데이터에서는 어렵기 때문에
경사하강법을 통해 w를 찾음 → Gradient discent algorithm
- Q2. Loss가 0이 되는 지점을 어떻게 찾을까요?
- A2.
## Loss Function Optimization
학습 목적의 최적 포인트를 찾자
- 골짜기 가장 밑바닥(Loss Function이 최소가 되는 지점)으로 내려갈 수 있는 현실적인 방법 → performance measure가 최대가 됨 (parametic learning 방법의 수학적인 정의)
- 각 지점에서 기울기 (gradient)가 가장 큰(가파른) 방향으로 내려갑니다
댓글남기기