[논문리뷰] MANIQA : Multi-Dimension Attention Network For No-Reference Image Quality Assessment
정말 오랜만의 포스팅입니다..
저는 요즘 기업연계 프로젝트가 끝나고 취업준비중입니다.
여기저기 지원하고 있지만 좋은소식은 아직 없네요🥲
이번 포스팅은 논문리뷰입니다.
이 논문은 기업연계 프로젝트에 사용한 모델인데요, 뒤늦게 리뷰를 올리게 되었습니다.
그럼 바로 시작하겠습니다.


Abstract에서는 논문의 전반적인 내용을 간략하게 언급하고 있습니다. 어떠한 이유로 MANIQA를 제안하게 되었는지, 모델의 구조는 어떠한 특징을 가지는지, 그리고 어떠한 성능을 보이는지 다음 슬라이드 부터 자세히 들여다 보겠습니다

Introduction입니다 이미지 품질 저하는 이미지가 순환되는 모든 단계에서 생길 수 있으며, 이런 시각 정보의 손실은 자율주행 자동차의 성능에 까지 영향을 미칠 수 있다고 합니다. 그래서 논문의 저자는 크게 4개의 layer로 구성된 NR-IQA를 위한 Multi-dimension Attention Network를 고안했다고 합니다.

Related work에서는 FR-IQA와 NR-IQA에 대한 비교와 NR-IQA의 간략한 특징, 기존의 CNN이 주를 이루던 Computer Vision Task에서 느낀 한계점과 이를 넘어서기 위해 Vision Transformer를 접목하게 된 배경에 대해 얘기하고 있습니다.
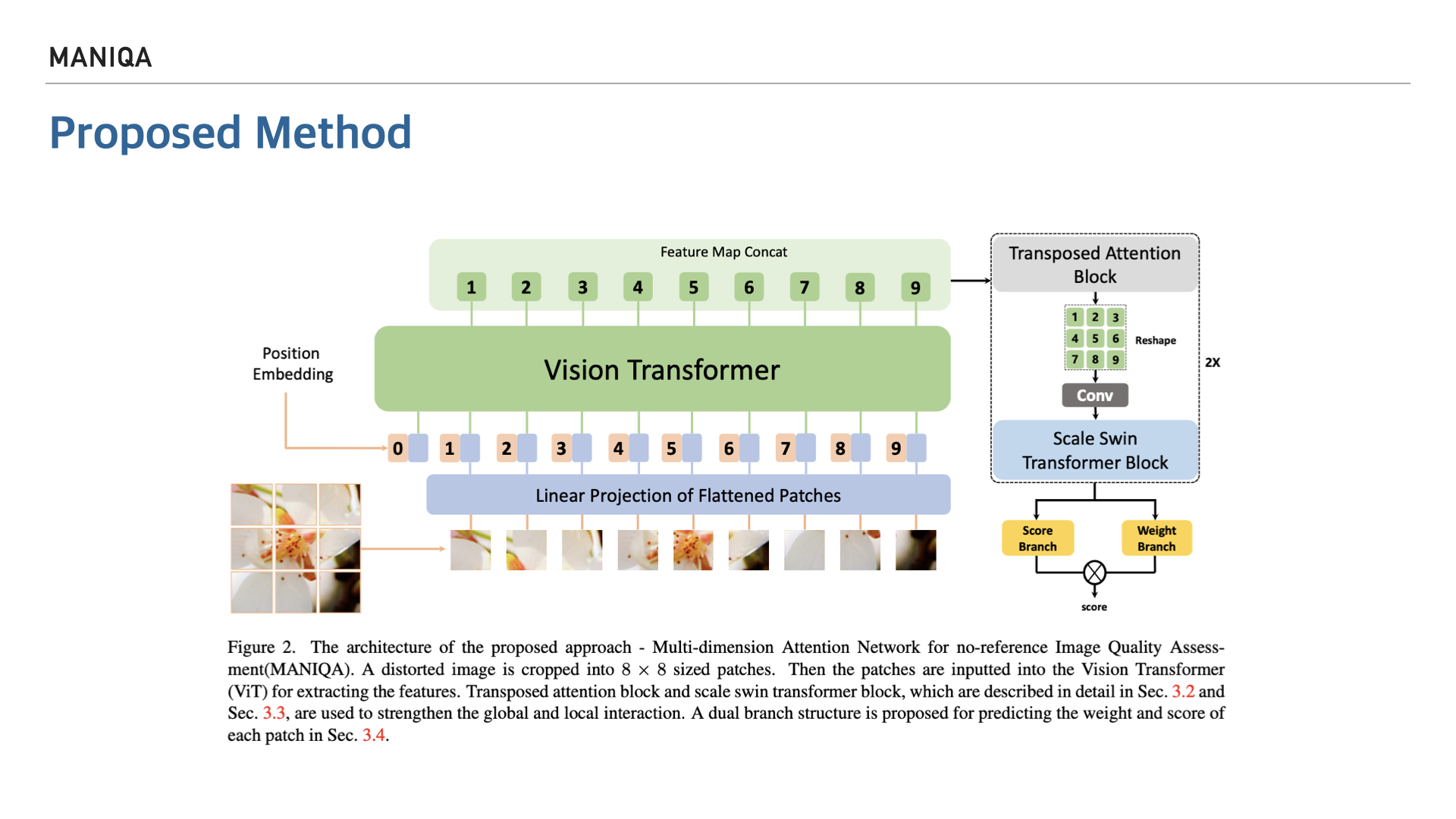
Proposed Method입니다. 이 논문에서의 목표는 추출된 이미지로 부터 다차원의 정보를 처리할 수 있는 모델을 개발하는 것입니다. 많은 내용이 있지만 핵심이 되는 내용은 아무래도 모델의 구조를 도식화 한 부분이라고 생각되어 해당 Figure를 가지고 MANIQA에 대해 설명드리겠습니다. MANIQA는 이전 슬라이드에서 보았듯 backbone이 CNN으로 이루어진 모델들의 한계를 극복하기 위해 Vision Transformer를 채용한 모델입니다. 다음 슬라이드부터 Step별로 input된 image를 어떻게 처리하는지 살펴보겠습니다.
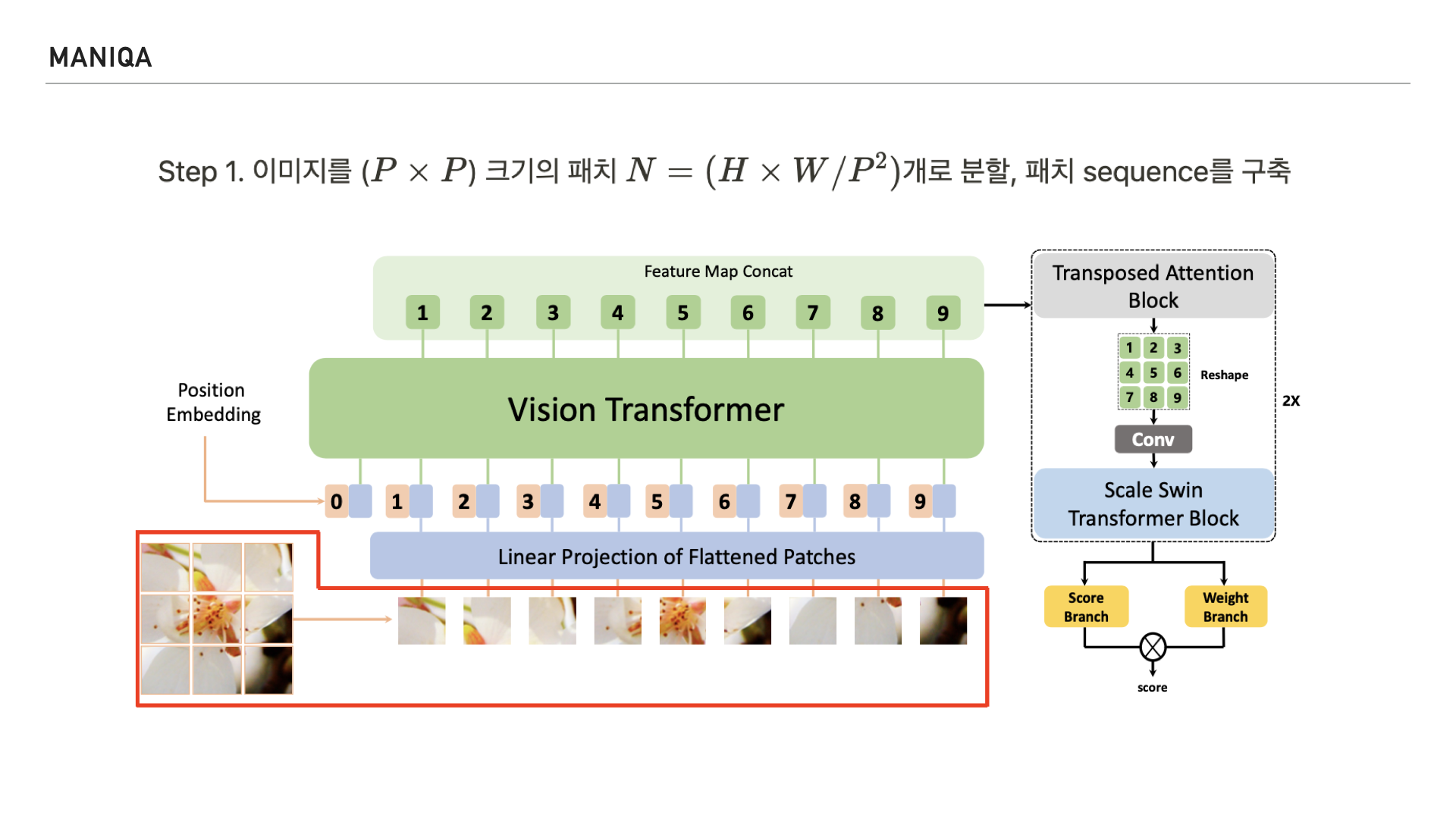
첫번째 Step에서는 input image를 정사각형의 패치 단위로 잘라 패치 sequence를 구축합니다.
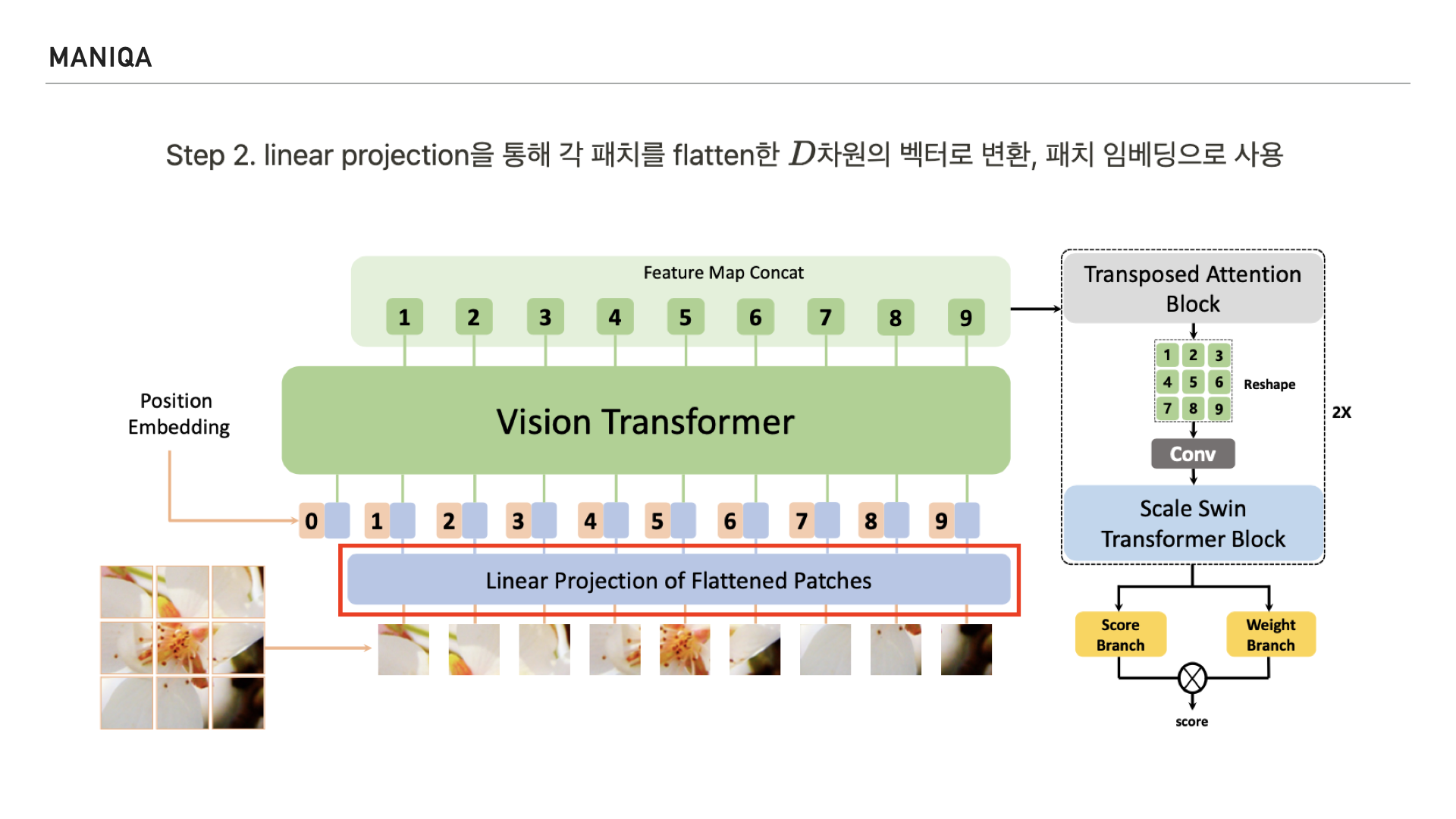
그런 다음 Linear Projection을 통해 각 패치를 flat한 D차원의 벡터로 변환하고 패치 임베딩으로 사용합니다.
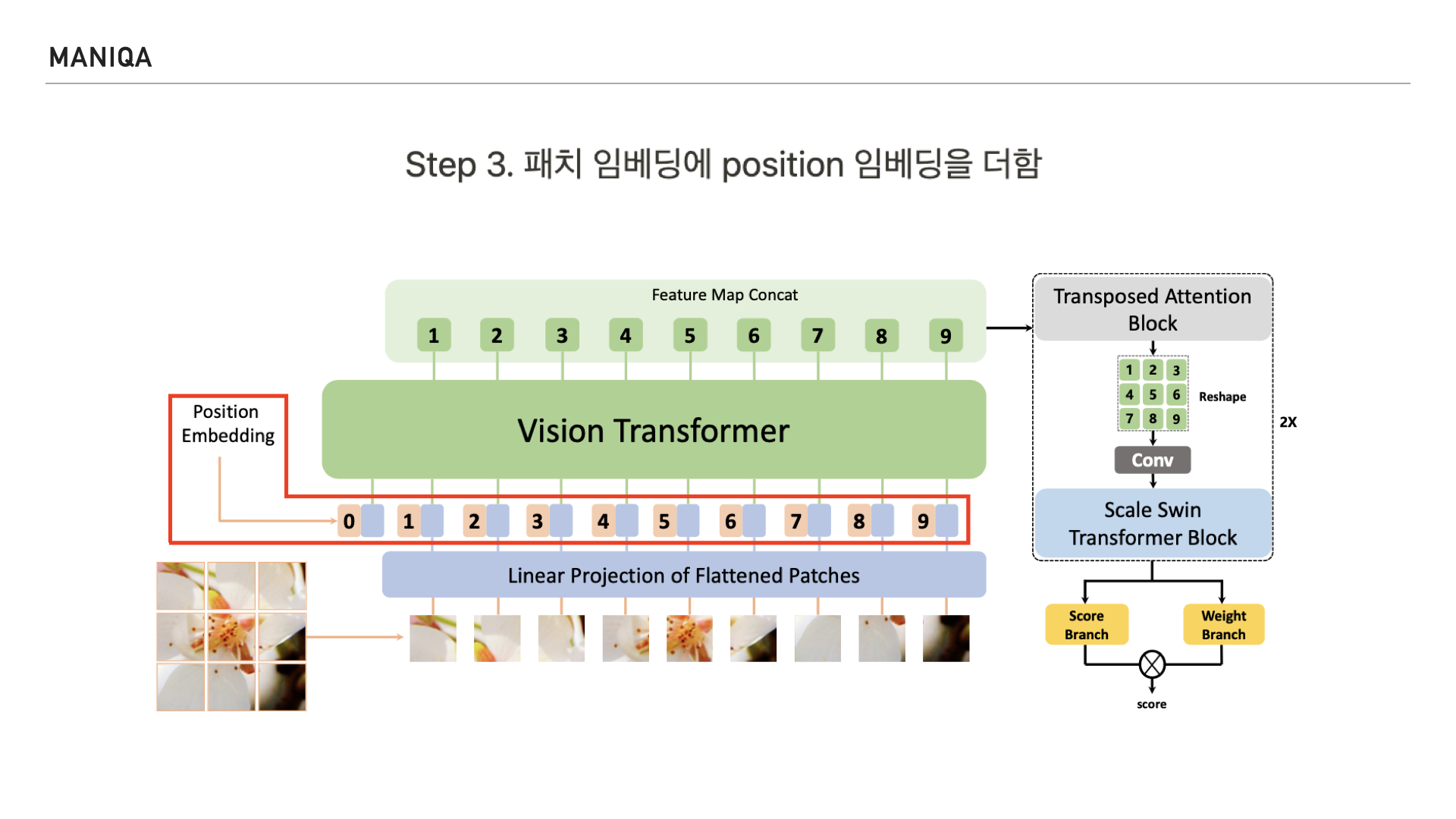
Step 2에서 변환된 패치 임베딩에 position 임베딩을 더하는데요 NLP를 다루는 Original Transformer에서 문장을 토큰화 하여 순서를 매기듯 Vision Transformer에서는 Image를 patch단위로 잘라 indexing 하여 문장처럼 순서대로 처리하는 걸 알 수 있습니다. Vision Transformer에서는 4가지의 position 임베딩을 시도하여 가장 효과가 좋은 1D(one dimension)의 임베딩 방식을 사용하였는데요 1-dimension positional embedding은 패치를 왼쪽 위부터 오른쪽 아래까지 살펴보는 raster order 방식의 임베딩 방식이라고 합니다.
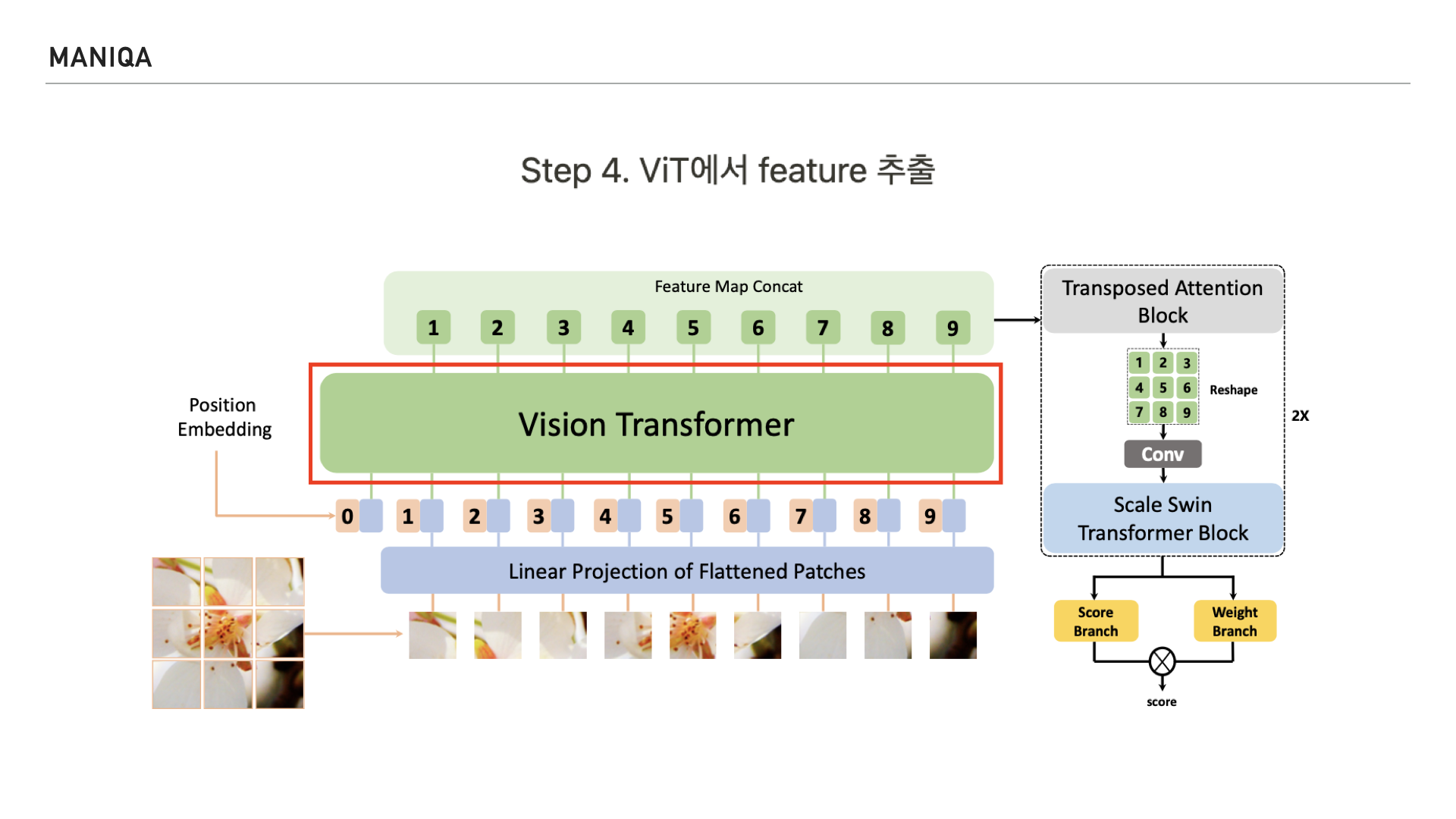
이렇게 Positional Embedding을 마친 patch들은 Vision Transformer에 들어가 feature를 추출하게 됩니다.
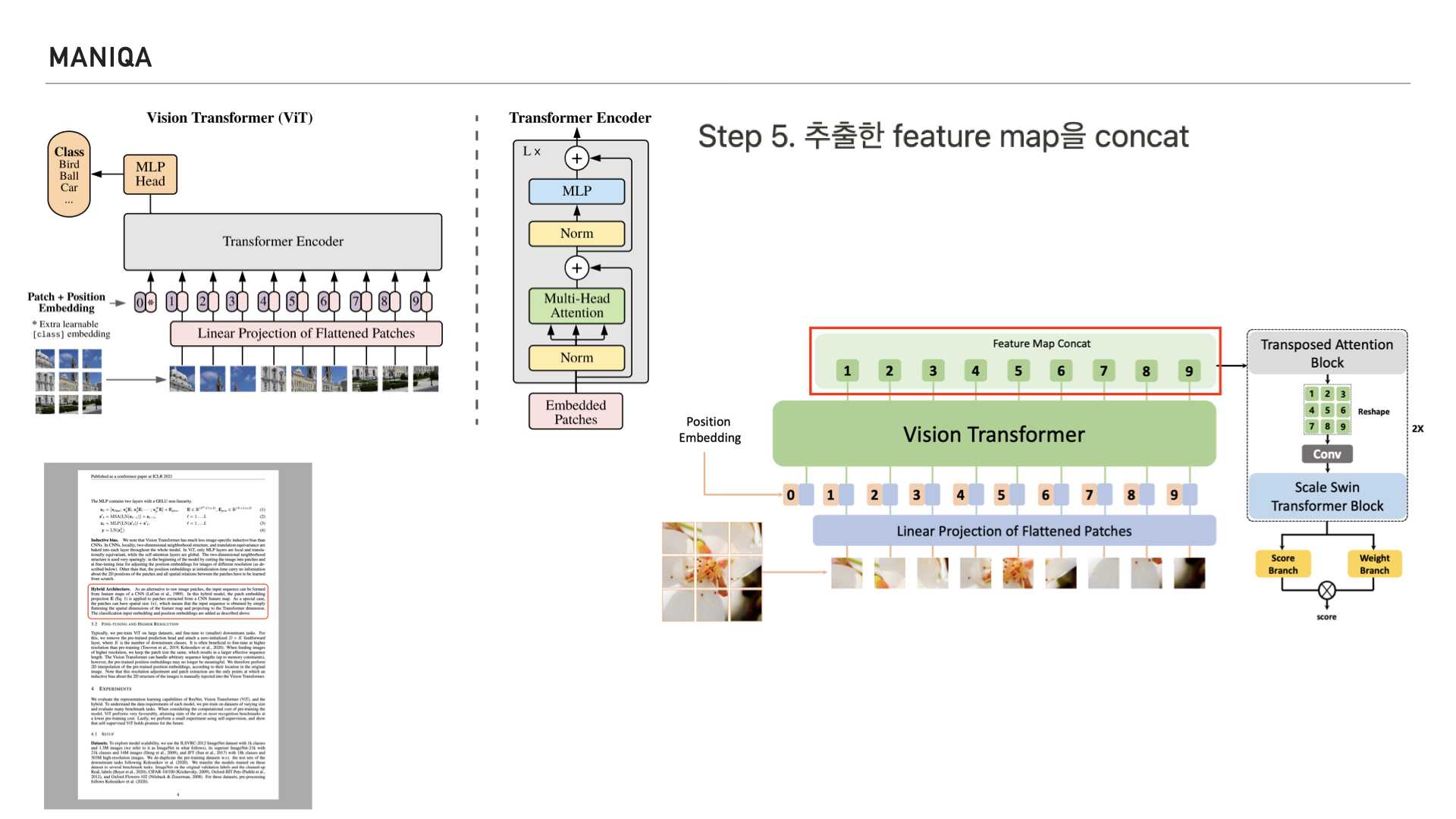
여기서 흥미로운 부분이 있는데요 왼쪽 위를 보시면 Original Vision Transformer의 그림이 있습니다.
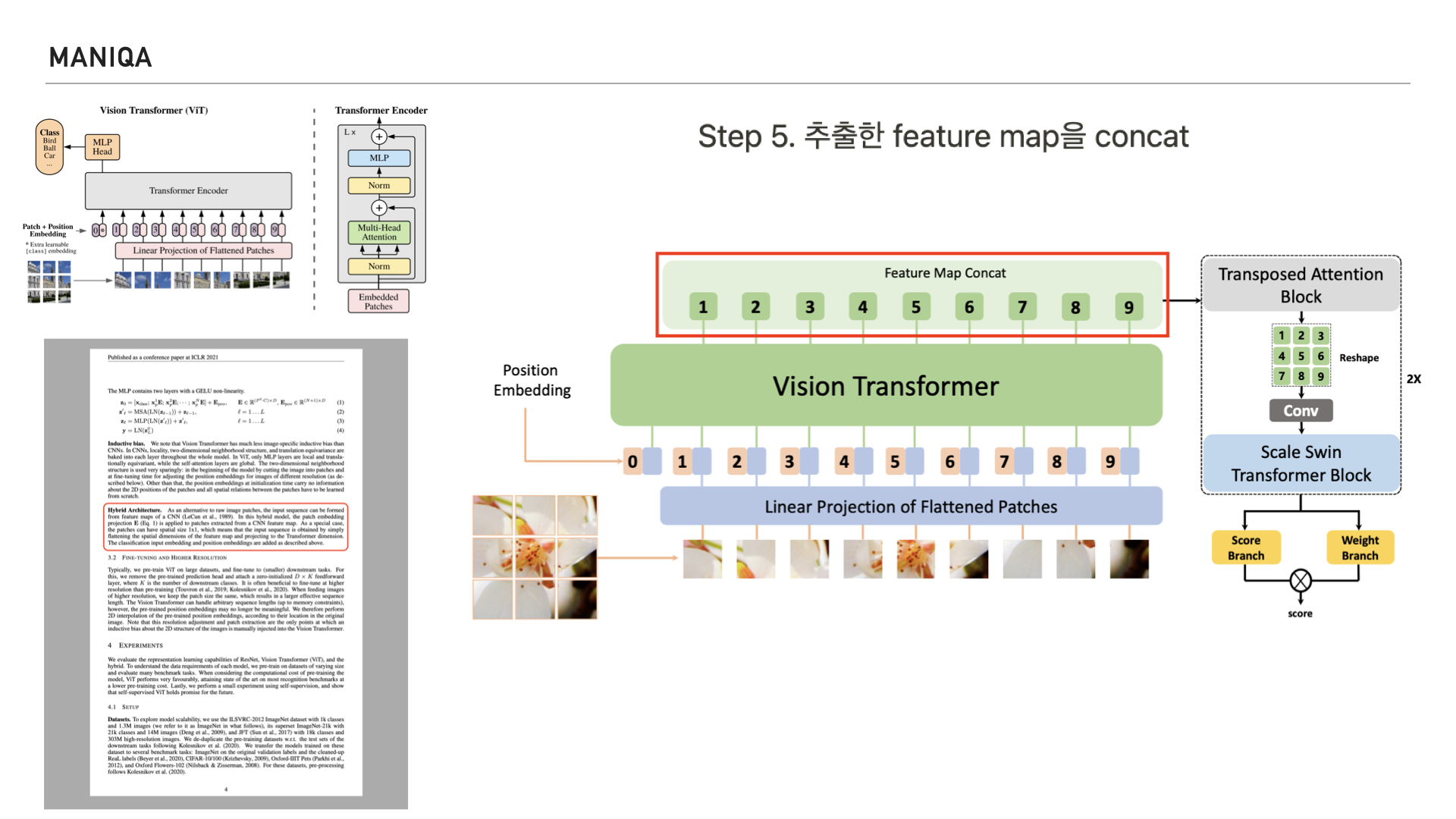
다시 오른쪽을 보시면 저희가 살펴보고 있는 MANIQA의 그림이 있는데요. Original Vision Transformer에서는 Transformer Encoder를 지나 MLP Head로 들어가는 반면, MANIQA에서는 Feature Map을 Concat한다고 되어있습니다.

이 부분은 ViT의 논문 4P에 언급되어있는 하이브리드 아키텍쳐라고 생각되는데요, ViT 논문의 내용을 살펴보면 Vision Transformer는 raw image가 아닌 CNN을 통해 추출한 raw image의 feature map을 활용하는 하이브리드 아키텍쳐로도 사용을 할 수 있다고 합니다.
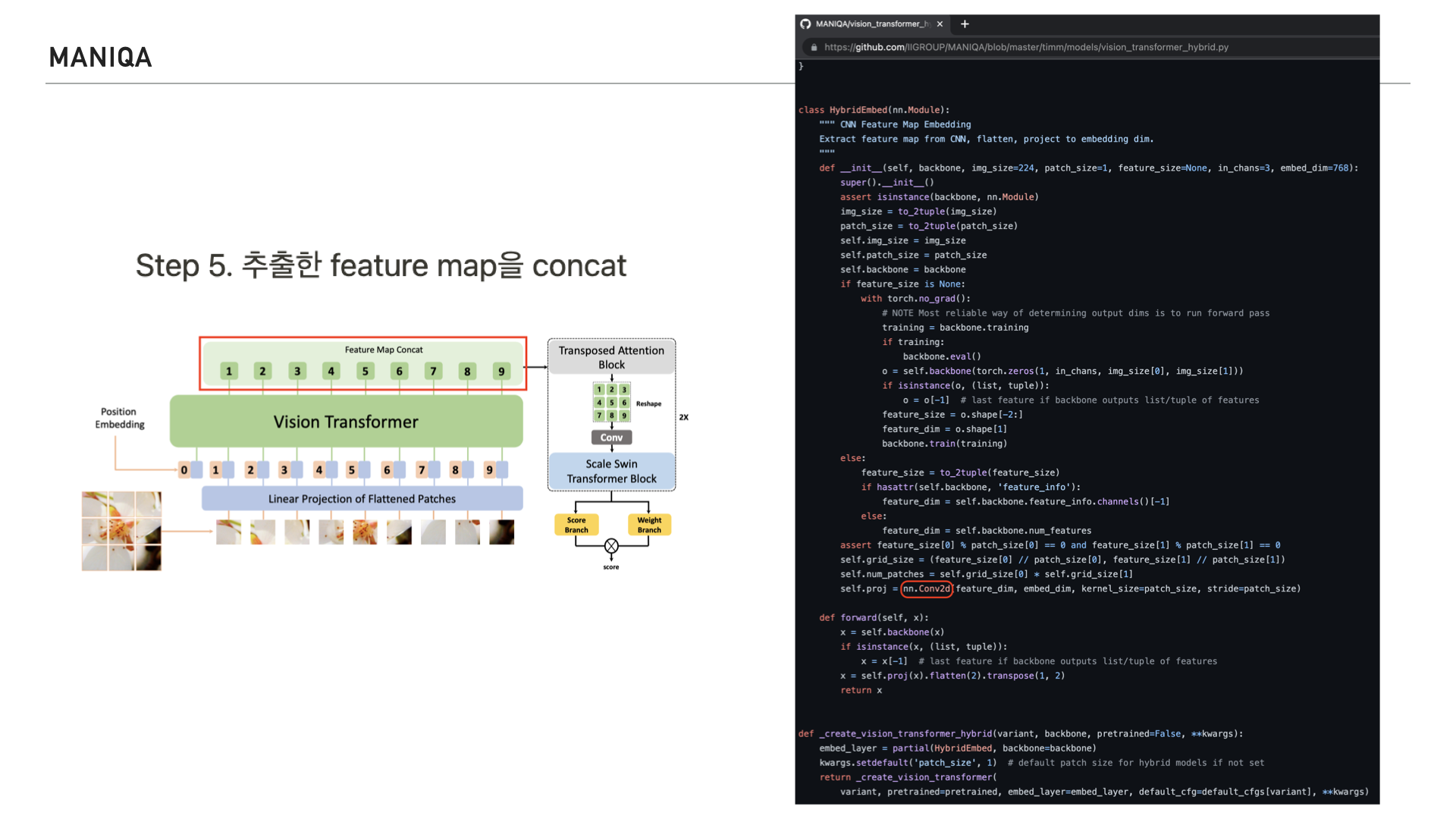
실제로 깃허브에 구현되어있는 공식 코드를 보면 convolution layer가 적용된다는 걸 확인할 수 있습니다.
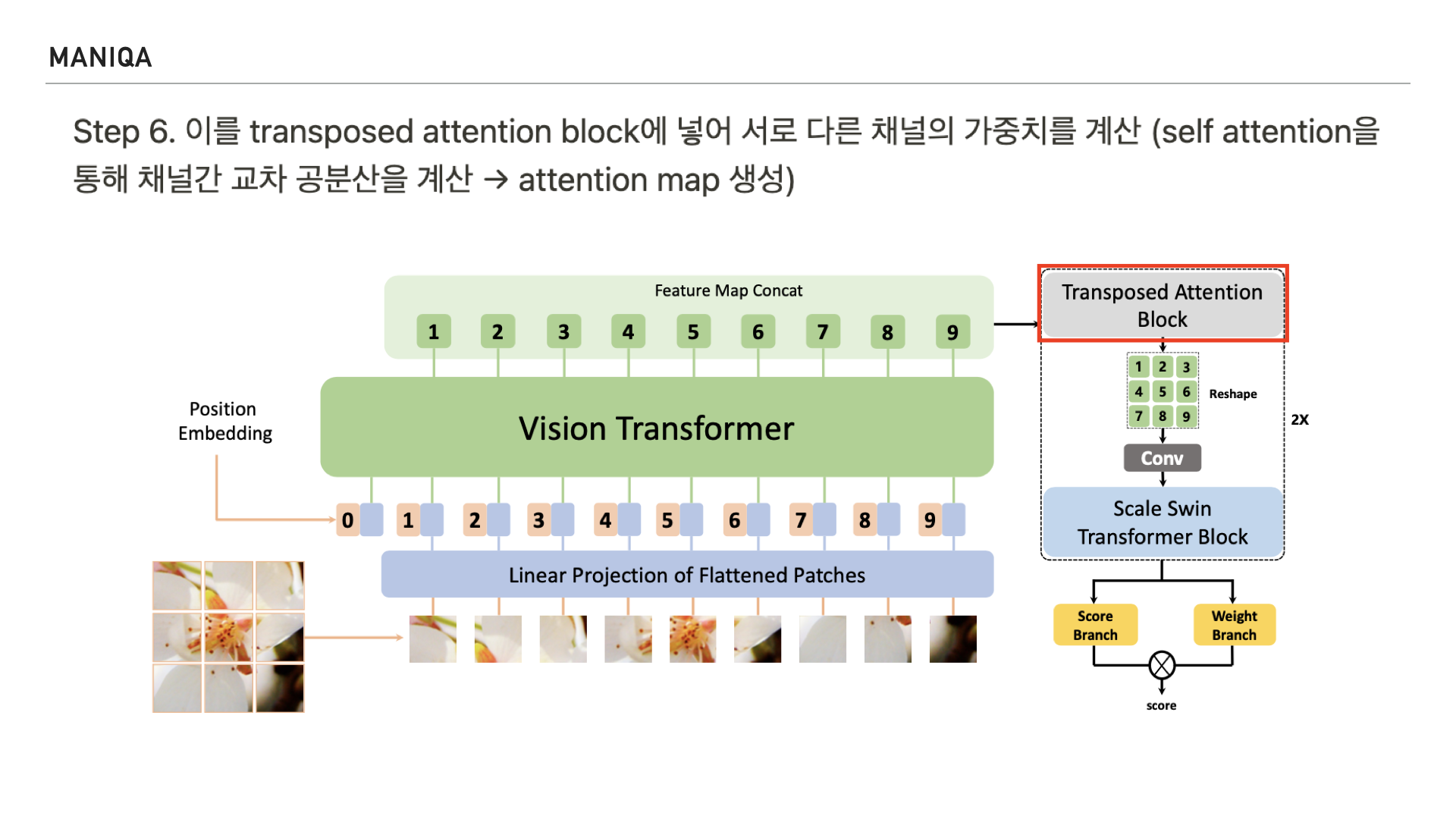
다음 Step에서는 이렇게 처리된 patch를 transposed attention block에 넣습니다. 여기서 중요한 개념인 self-attention이 등장하는데요, 다음 슬라이드에서 자세히 살펴보겠습니다.
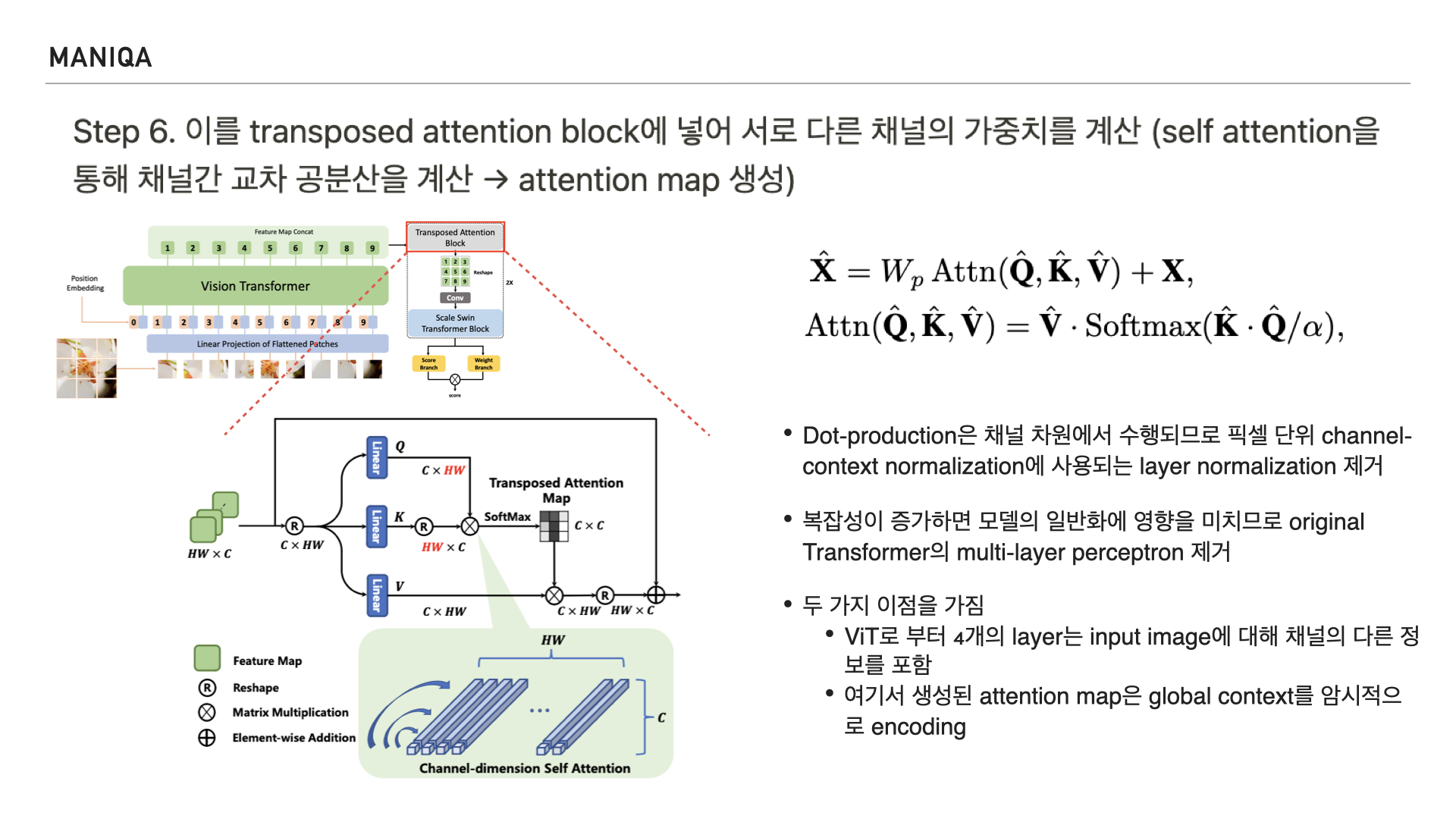
Self attention은 NLP에서 사용되는 transformer의 핵심 구성 요소로, 쿼리, 키, 밸류를 만들어 문맥적 관계성을 추출하는 과정을 말합니다. 인코더와 디코더 블록 모두에서 수행되며 교차 공분산을 계산한다고 하는데요, 공분산은 공분산(共分散, 영어: covariance)은 2개의 확률변수 간 선형 관계를 나타내는 값을 말합니다. 교차 공분산은 공분산을 여러 차원에서 일반화하는 개념이라고 저는 받아들였는데요, 채널간의 공분산을 다차원으로 계산하여 attention map을 생성하는 것으로 생각됩니다. 확률 이론과 통계에 관한 개념이다보니 깊이가 있는 이해를 하려면 조금 더 시간이 필요하다고 생각했습니다. 그리고 MANIQA에서는 Transposed attention block의 전반적인 process를 오른쪽과 같이 표현하였는데요,
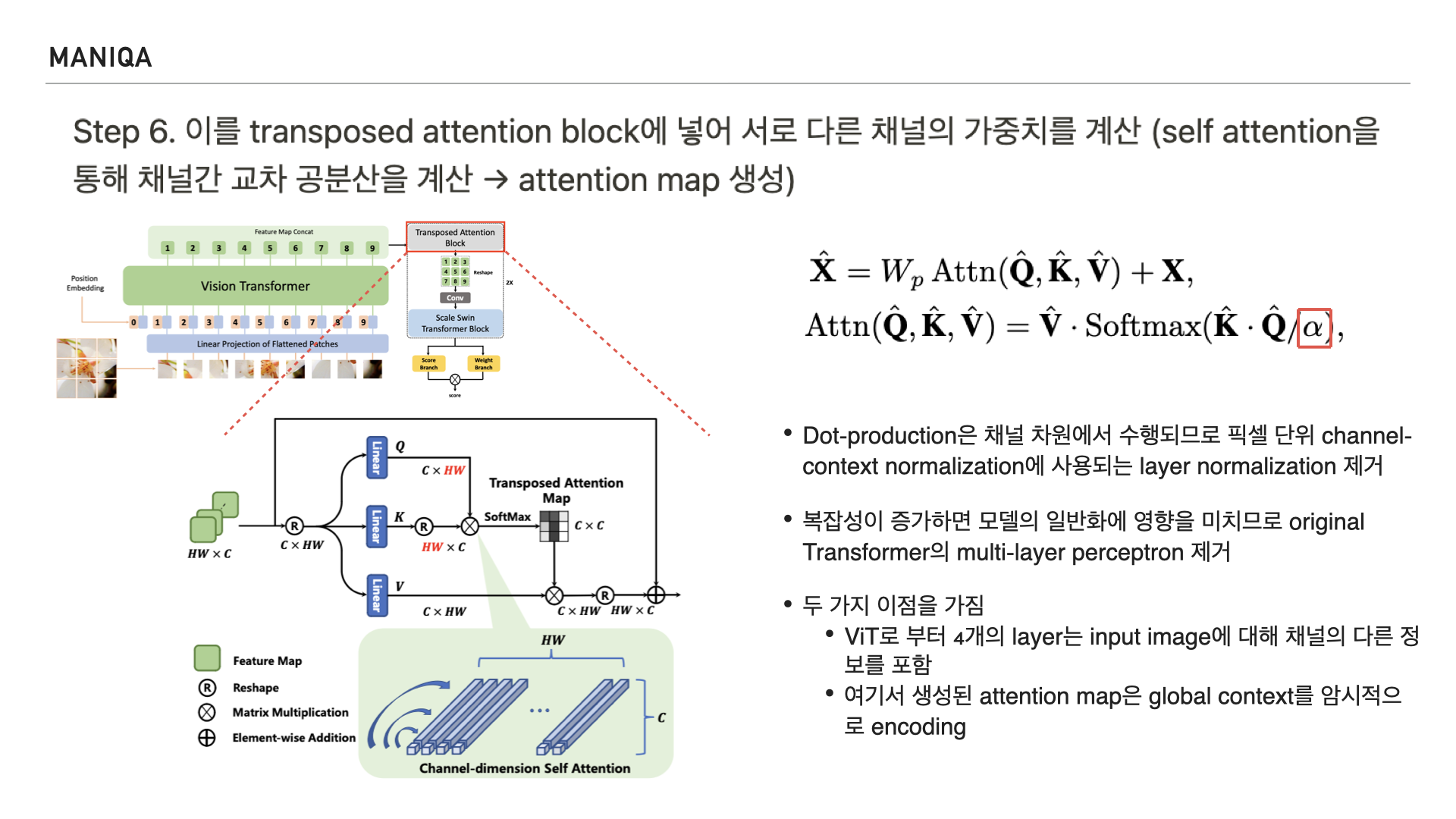
알파의 경우 query, key, value를 나타내며 기존의 구조와는 다르게 layer normalization과 multi-layer perceptron을 제거했다고 합니다. 이를 통해 다른 채널의 정보를 포함할 수 있게 되었고, attention map에서 global context를 encoding하게 되었다고 합니다.
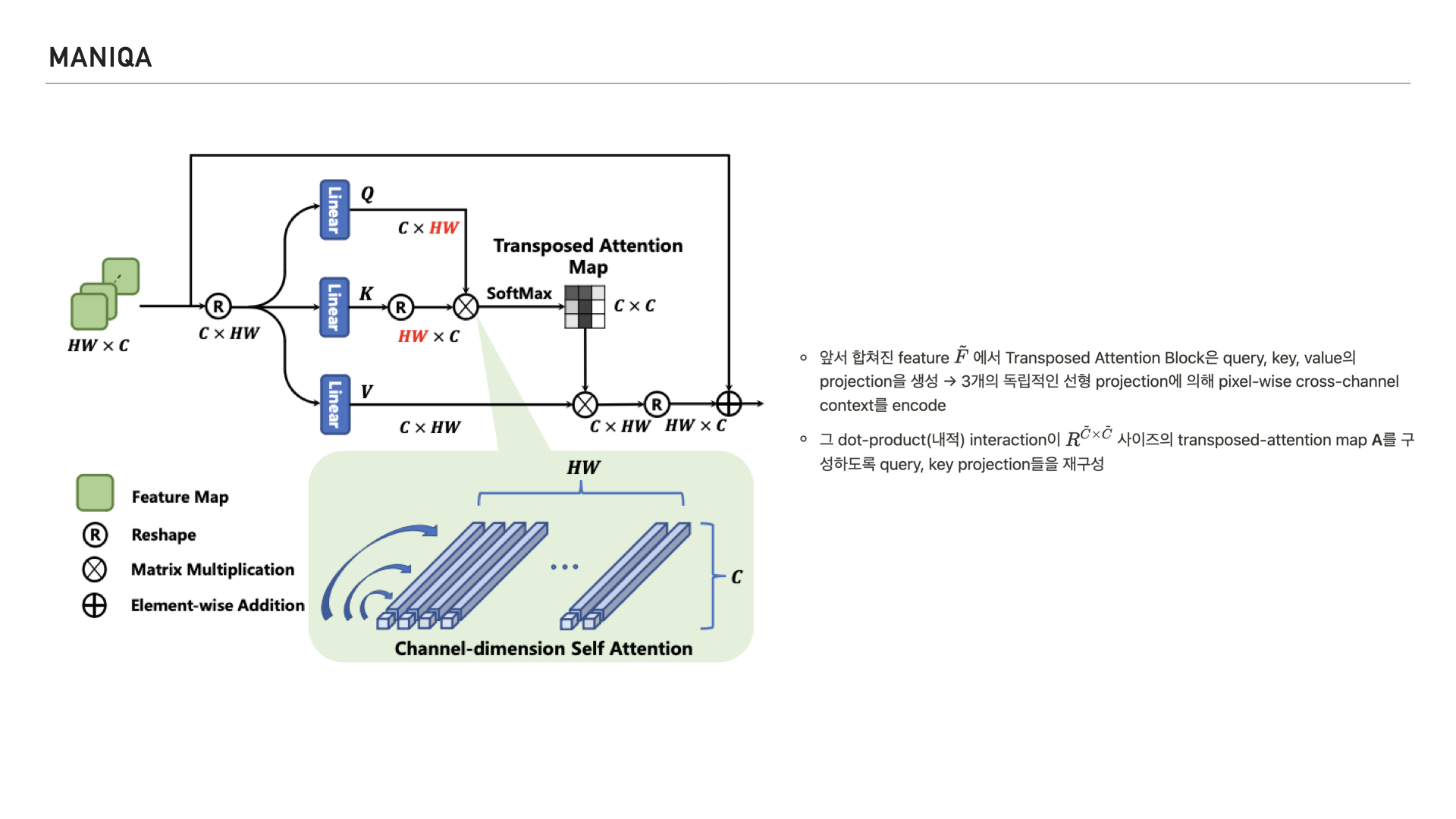
조금 더 자세히 들여다보면 기존 Self-Attention에서 키-쿼리와 dot-production의 상호작용은 spatial dimension에서 패치 간 global connection을 구축하는데 이 과정은 다른 채널 간의 풍부한 정보를 무시한다고 합니다.
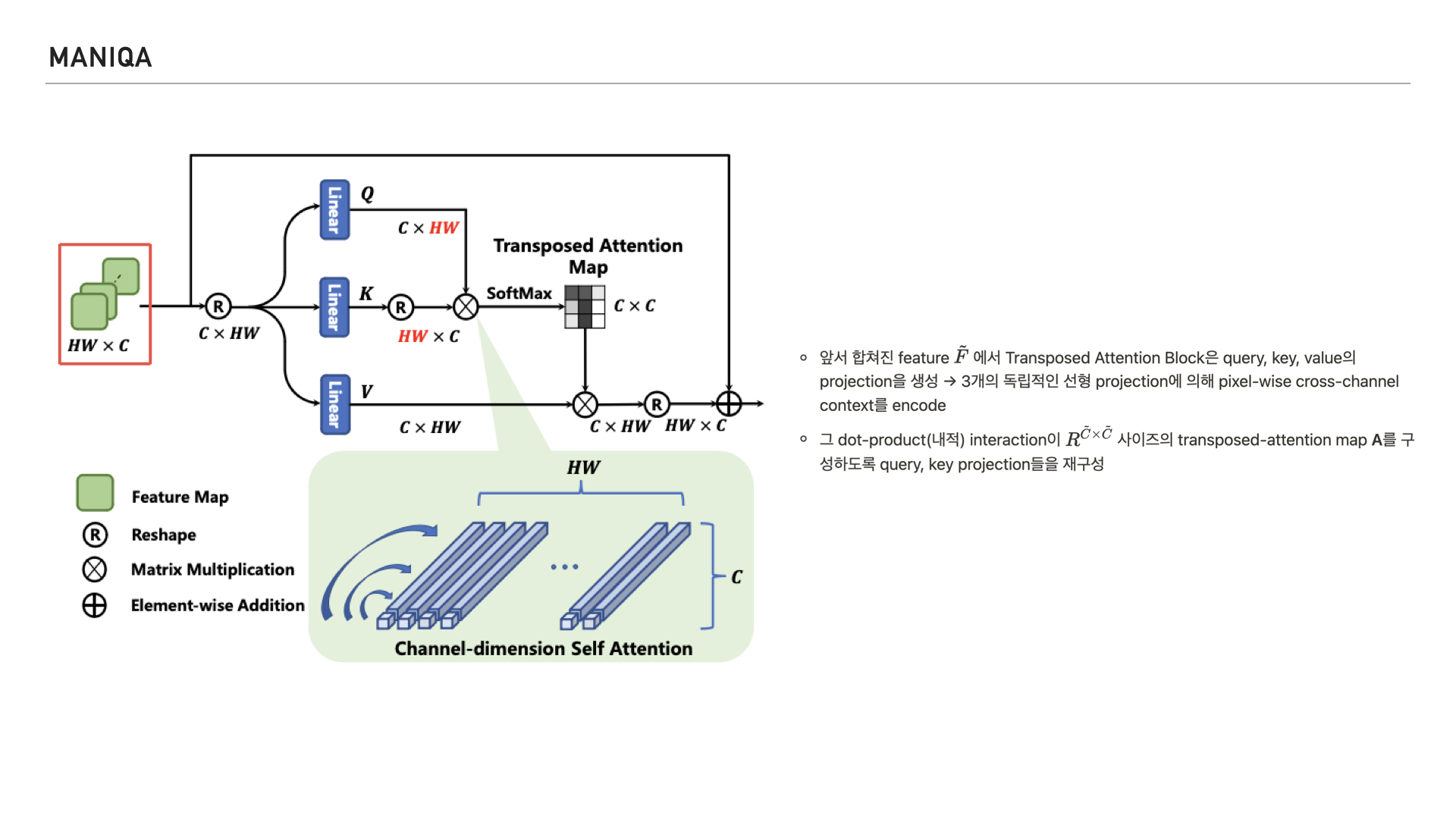
이를 완화하기 위해 제안된 것이 왼쪽에 보이는 Transposed Attention Block이고 이 블록은 global context를 암시적으로 인코딩하는 attention map을 생성하기 위해 spatial dimension이 아닌 채널 전체에 self attention을 적용한다고 합니다.
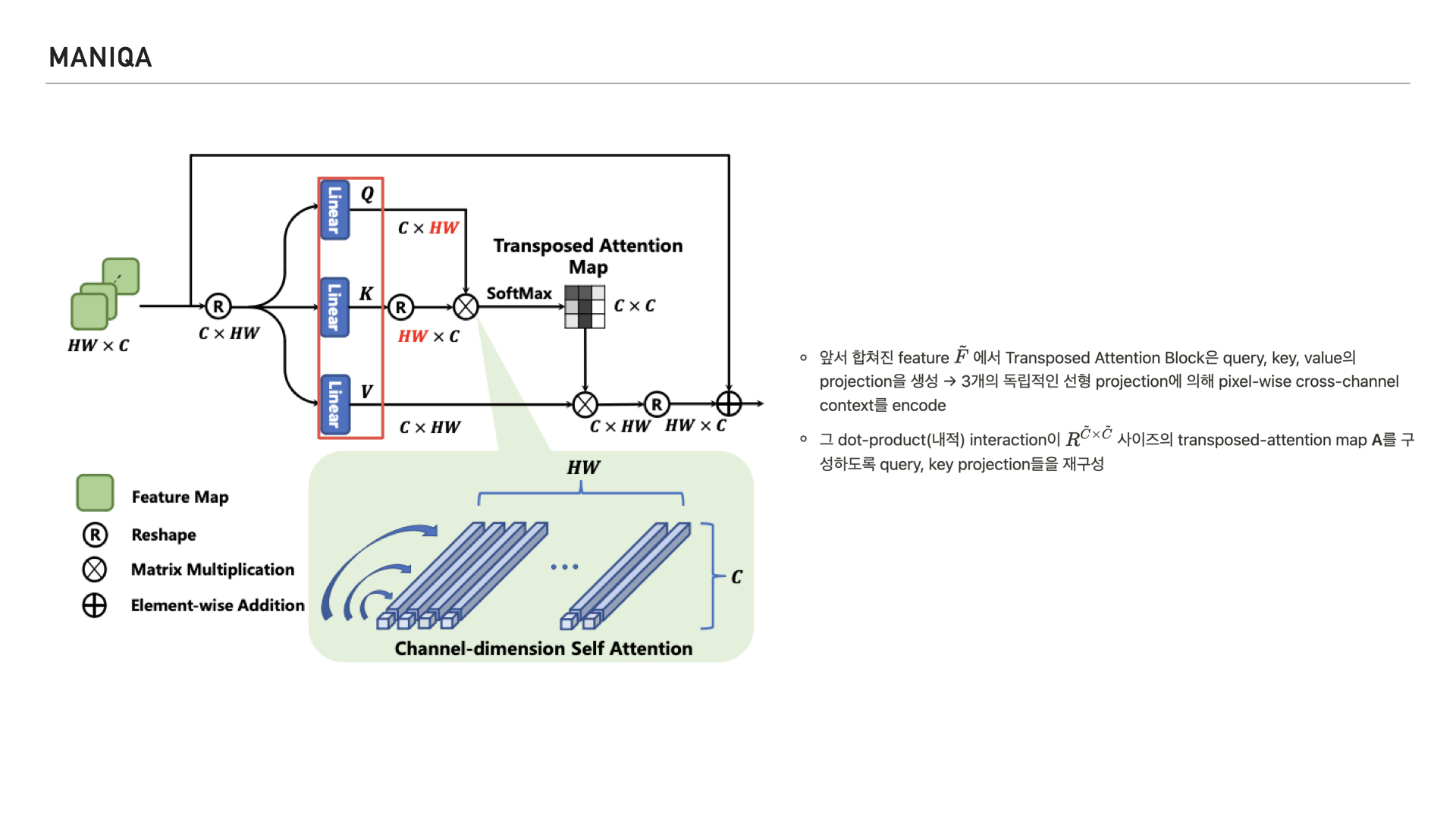
그림을 들여다보면 이미지의 feature를 받아 쿼리, 키, 밸류의 projection을 생성하고 3개의 독립적인 선형 projection에 의해 pixel-wise cross-channel context를 인코딩 한다고 합니다.
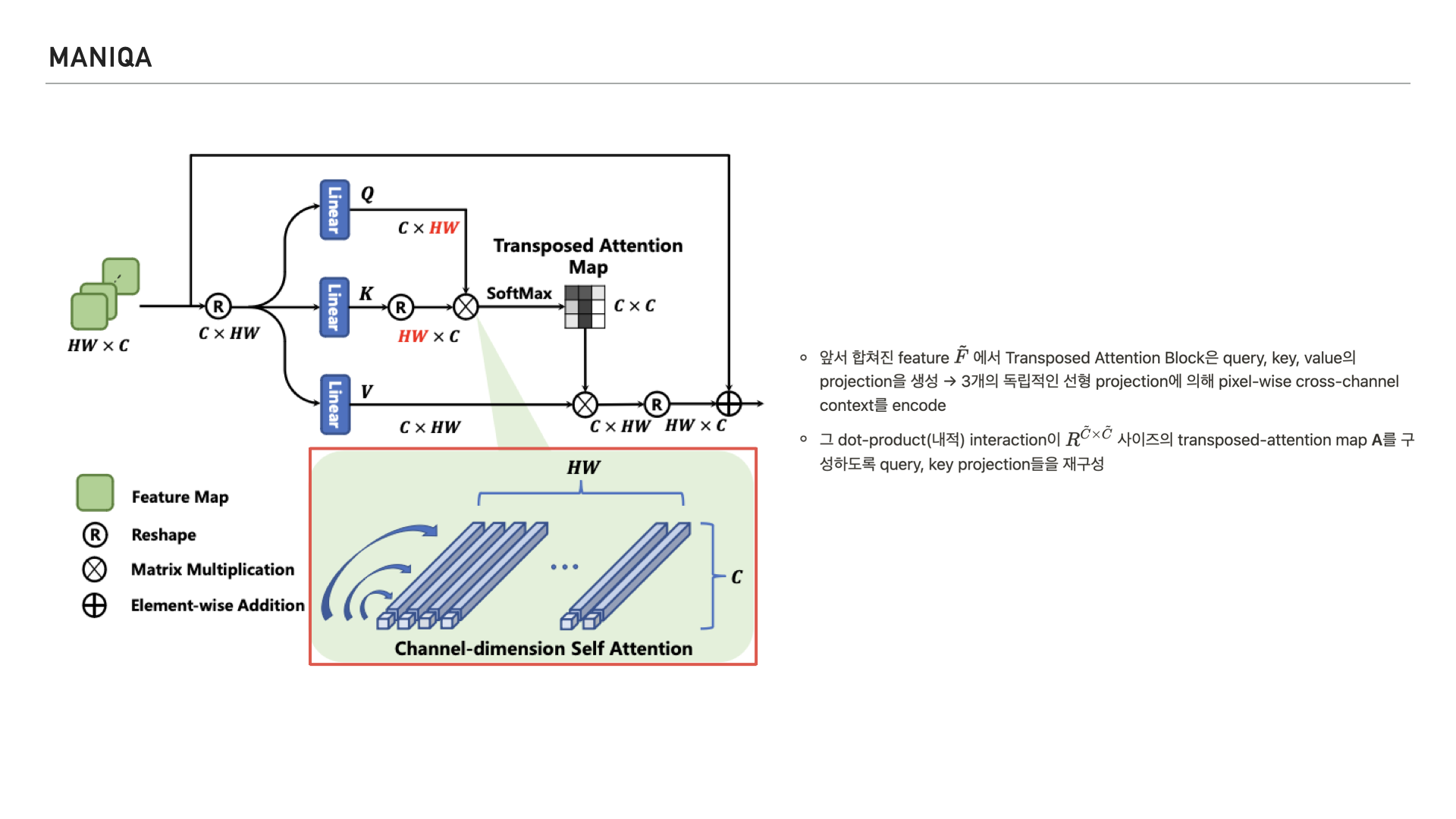
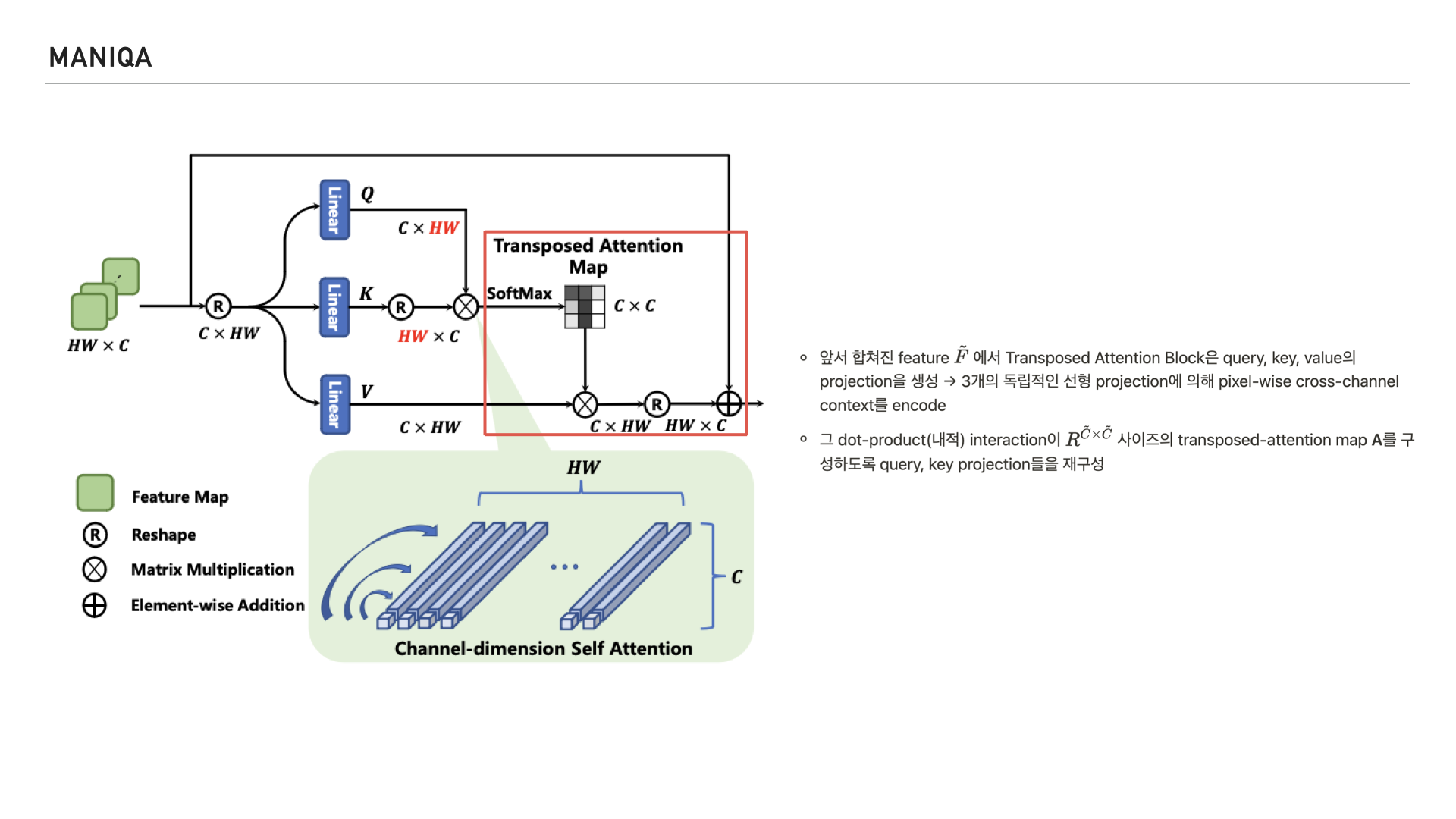
그리고 이런 연산이 transposed-attention map을 구성할 수 있게 쿼리, 키 projection을 재구성 한다고 합니다.
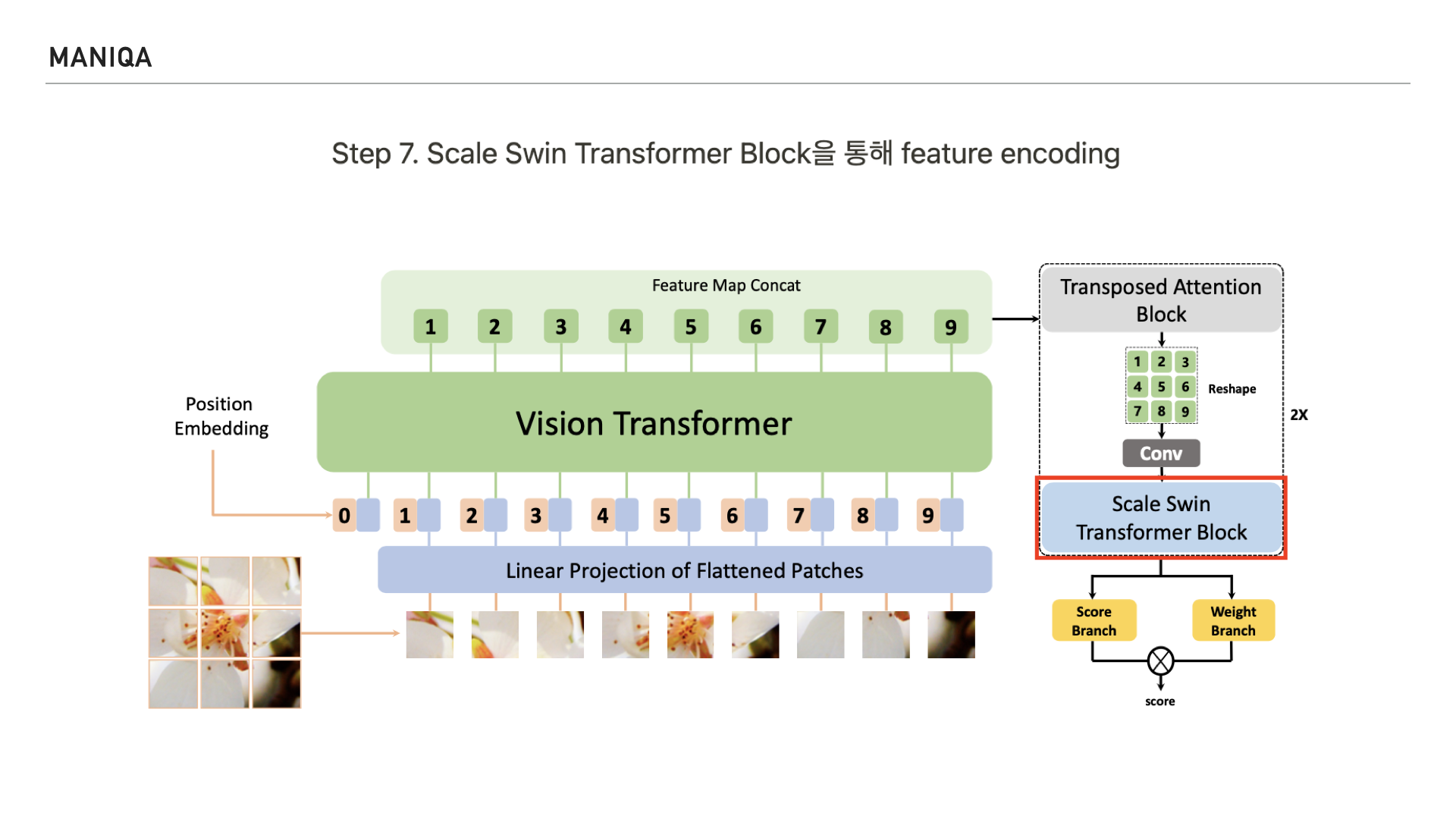
다음 Step에서는 Scale Swin Transformer Block을 통해 feature를 인코딩합니다.
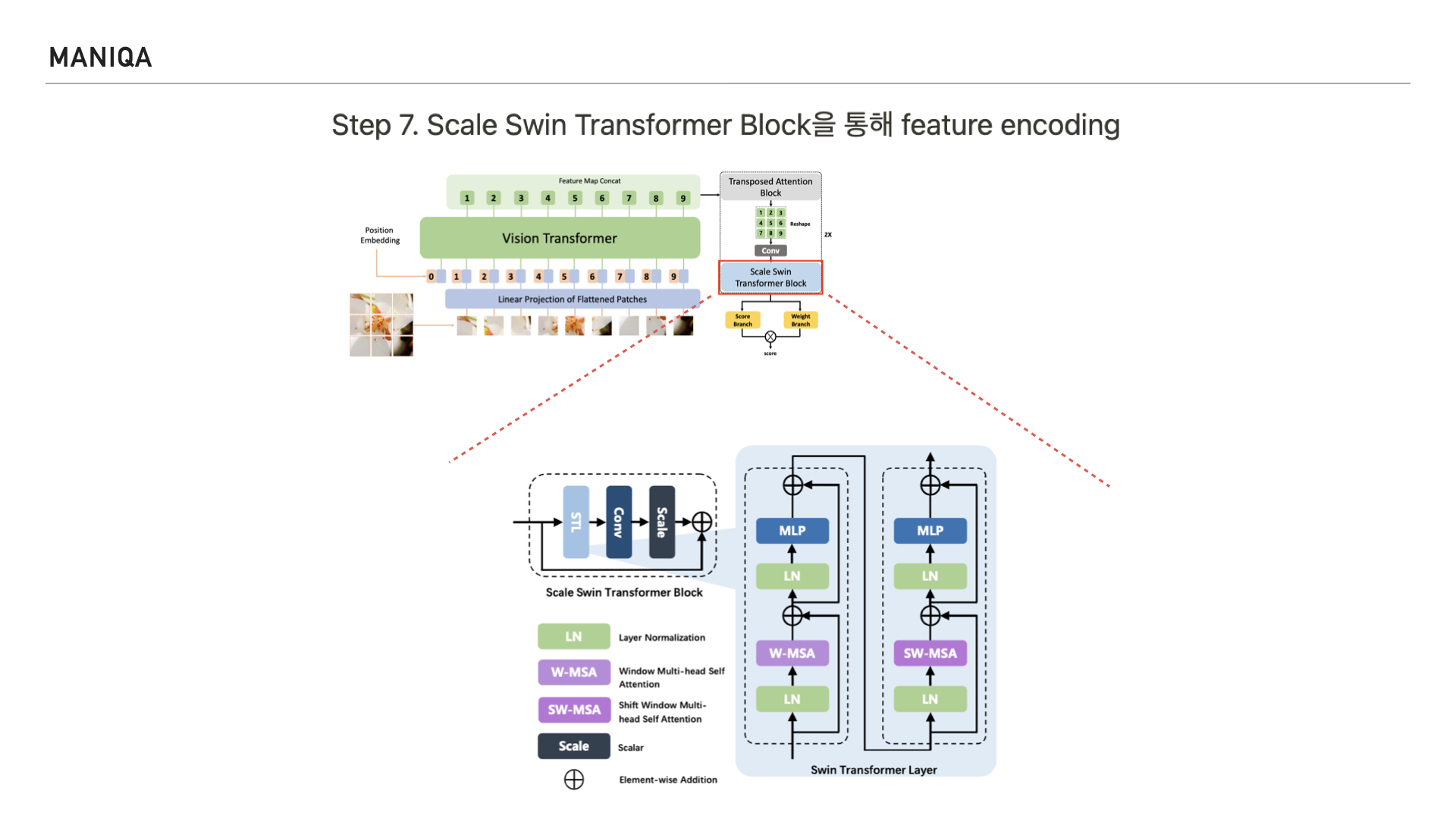
그림과 같이 Scale Swin Transformer Block은
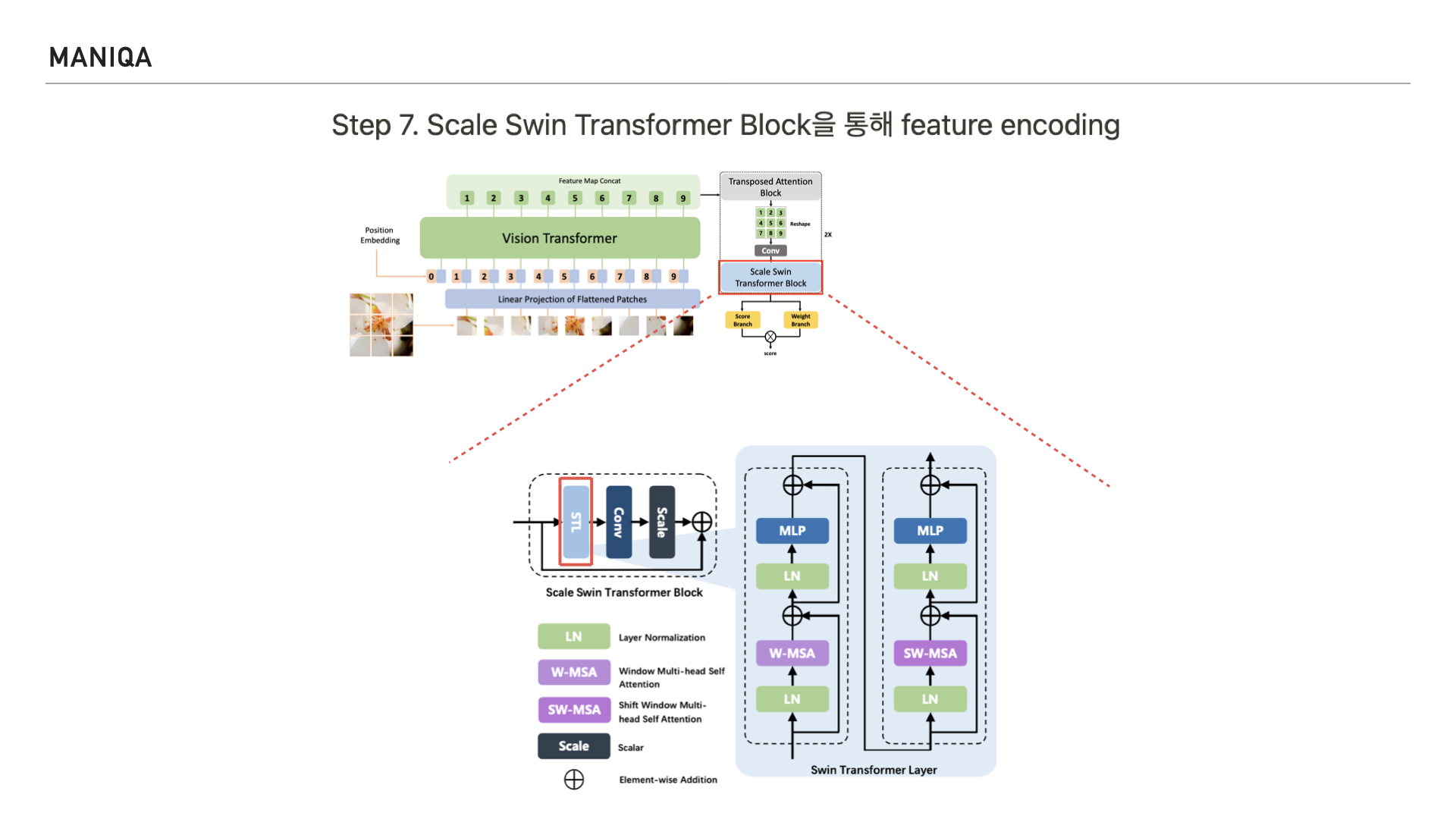
Swin Transformer Layer와
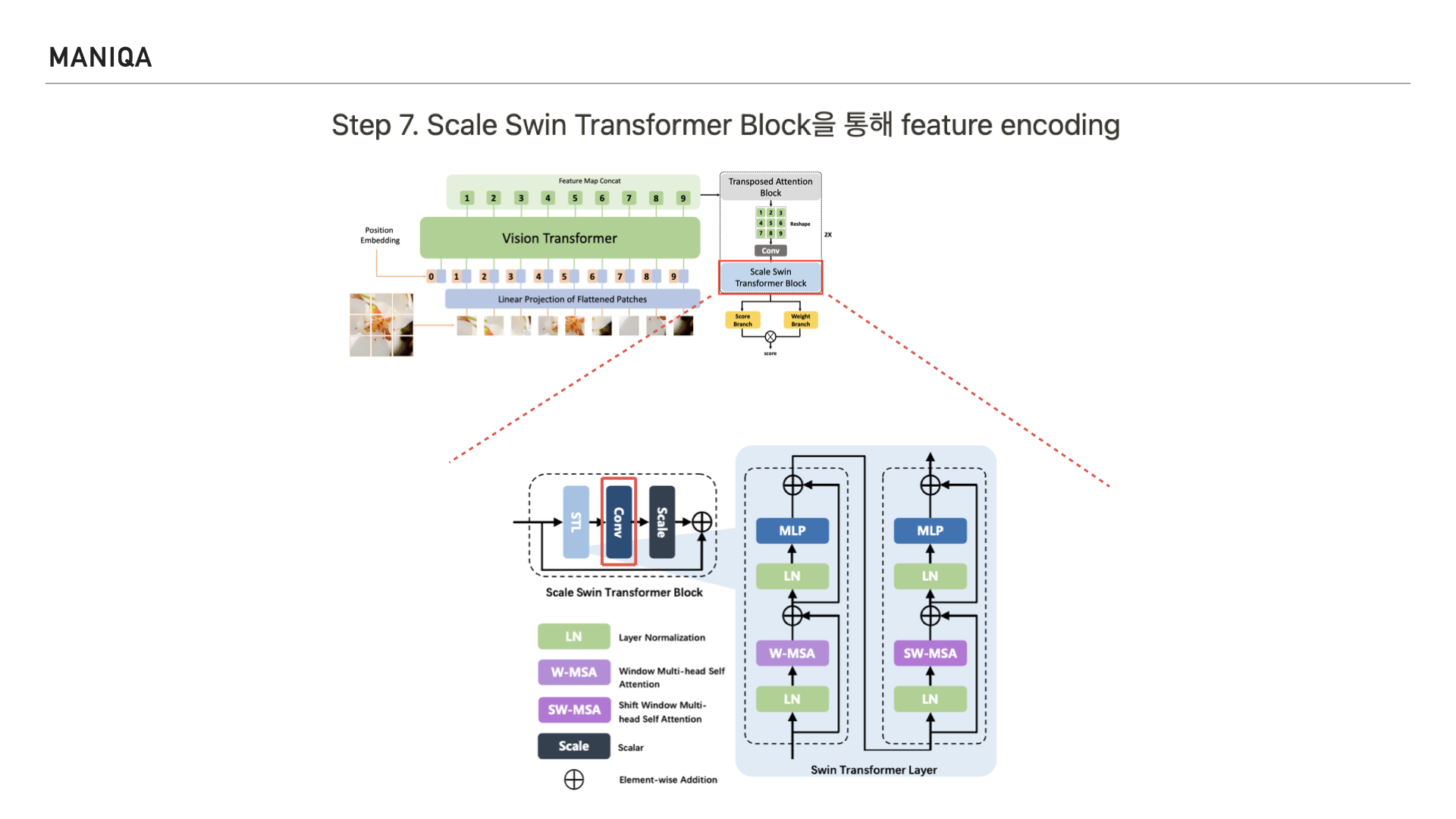
Convolution Layer로 구성됩니다.
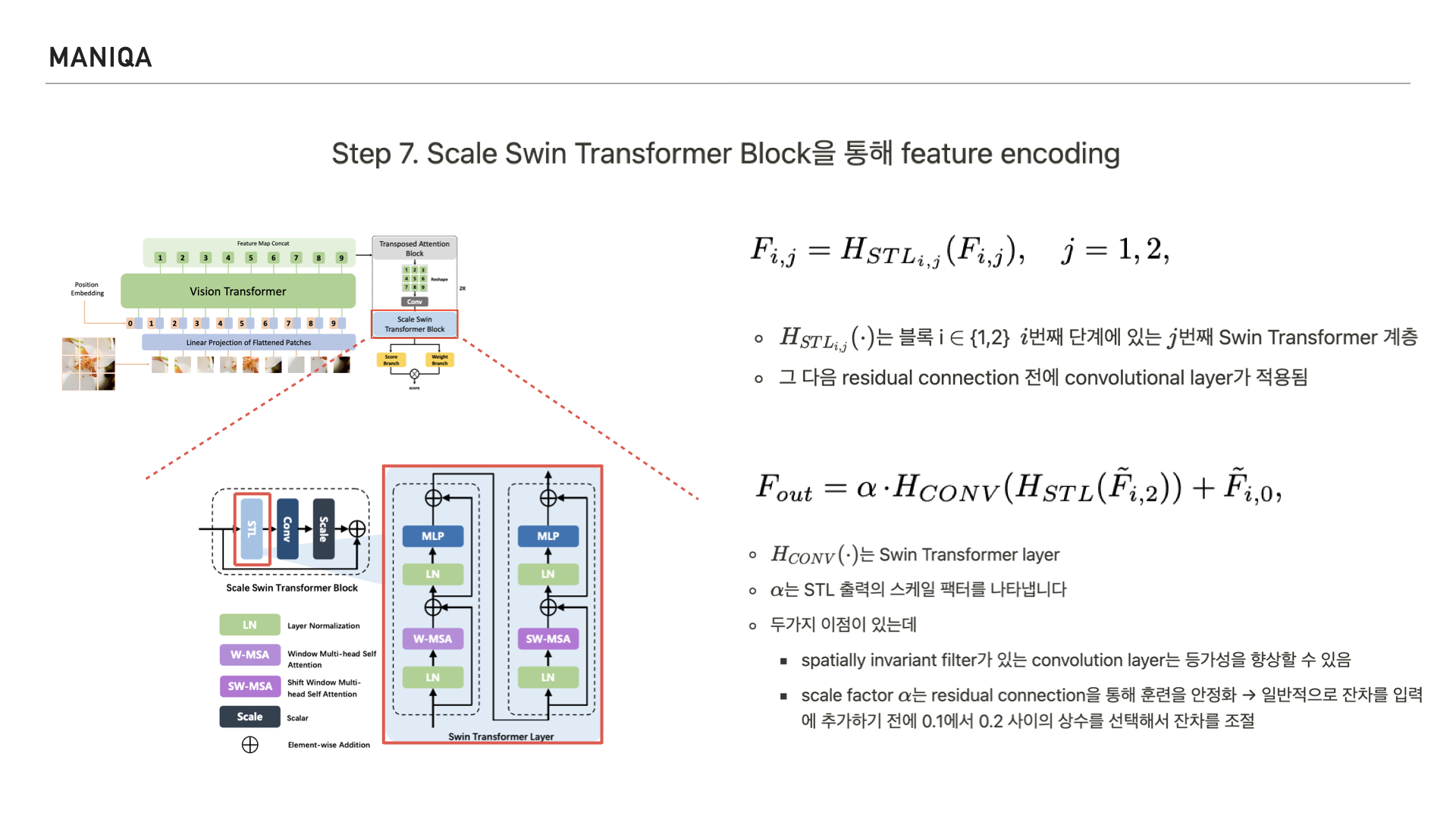
Input feature fi가 주어지면 먼저 Swin Transformer Layer의 2 계층을 통과해 feature를 인코딩합니다.
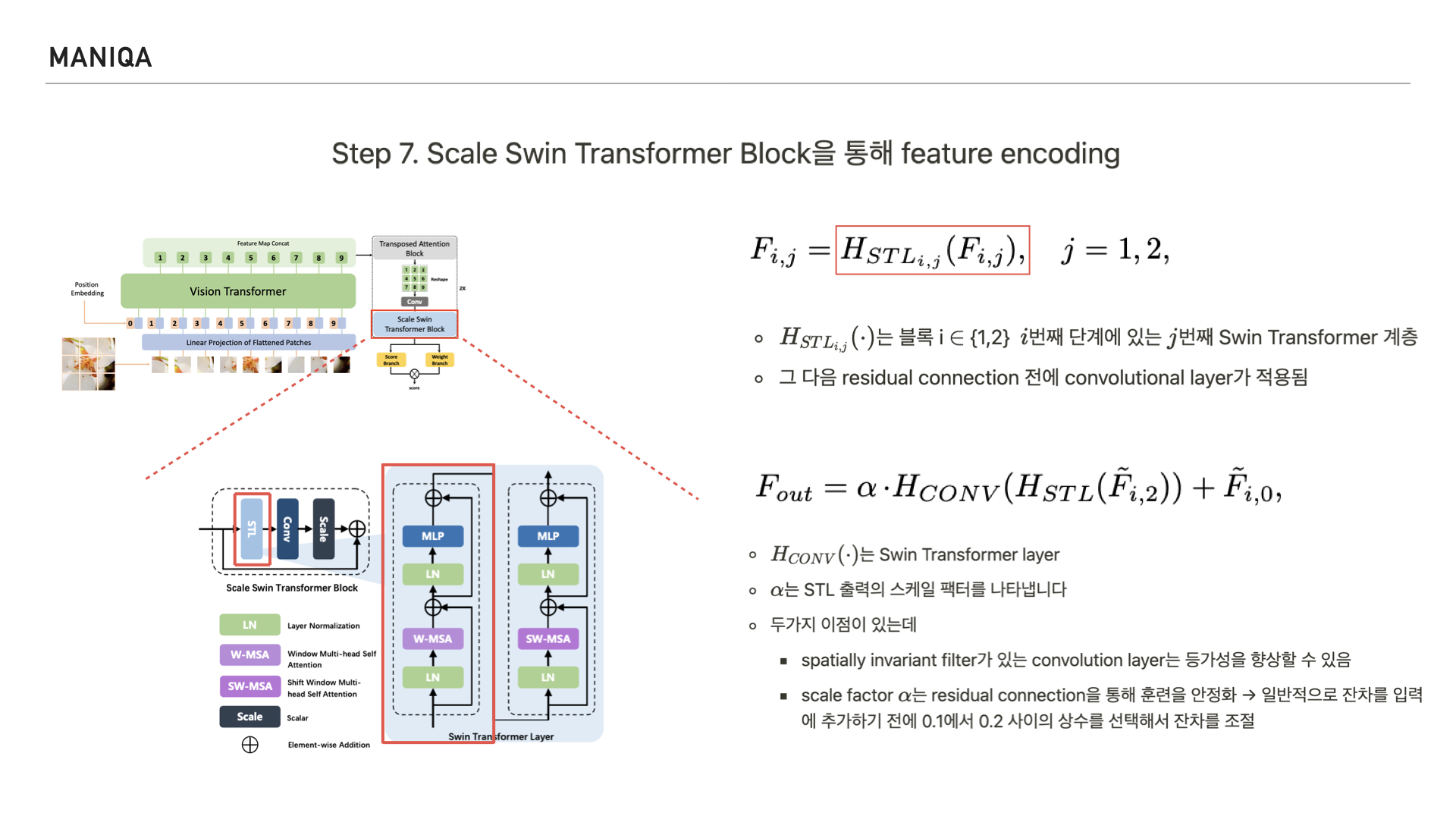
논문에서는 이 과정을 식으로 표현했는데요, 표시한 부분은 블록 i번째 단계에 있는 j번째 Swin Transformer 계층이라고 합니다.
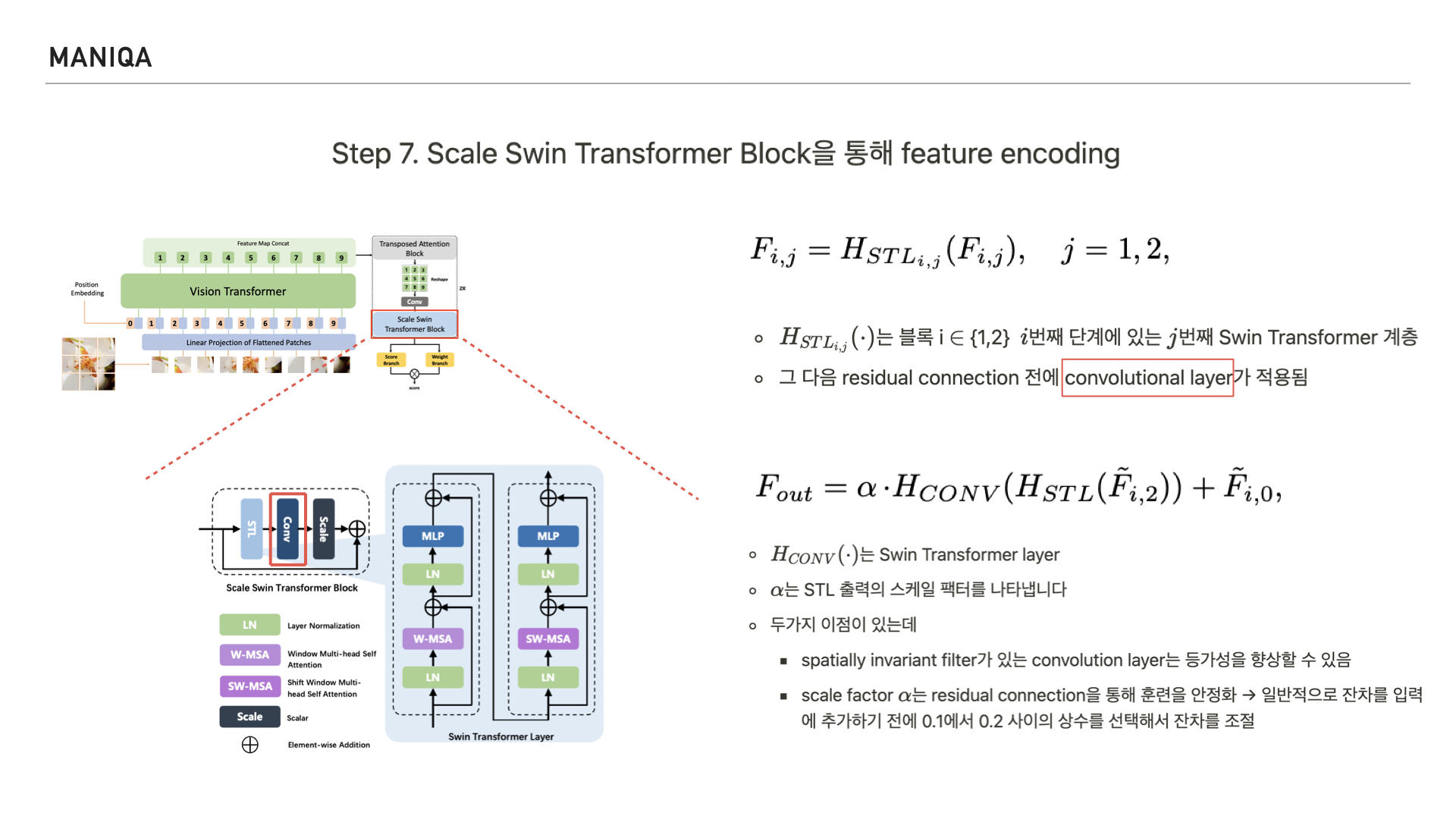
Swin Transformer Layer를 지나면 residual connection을 맺게 되는데 그 전에 convolution layer를 지나게 됩니다.
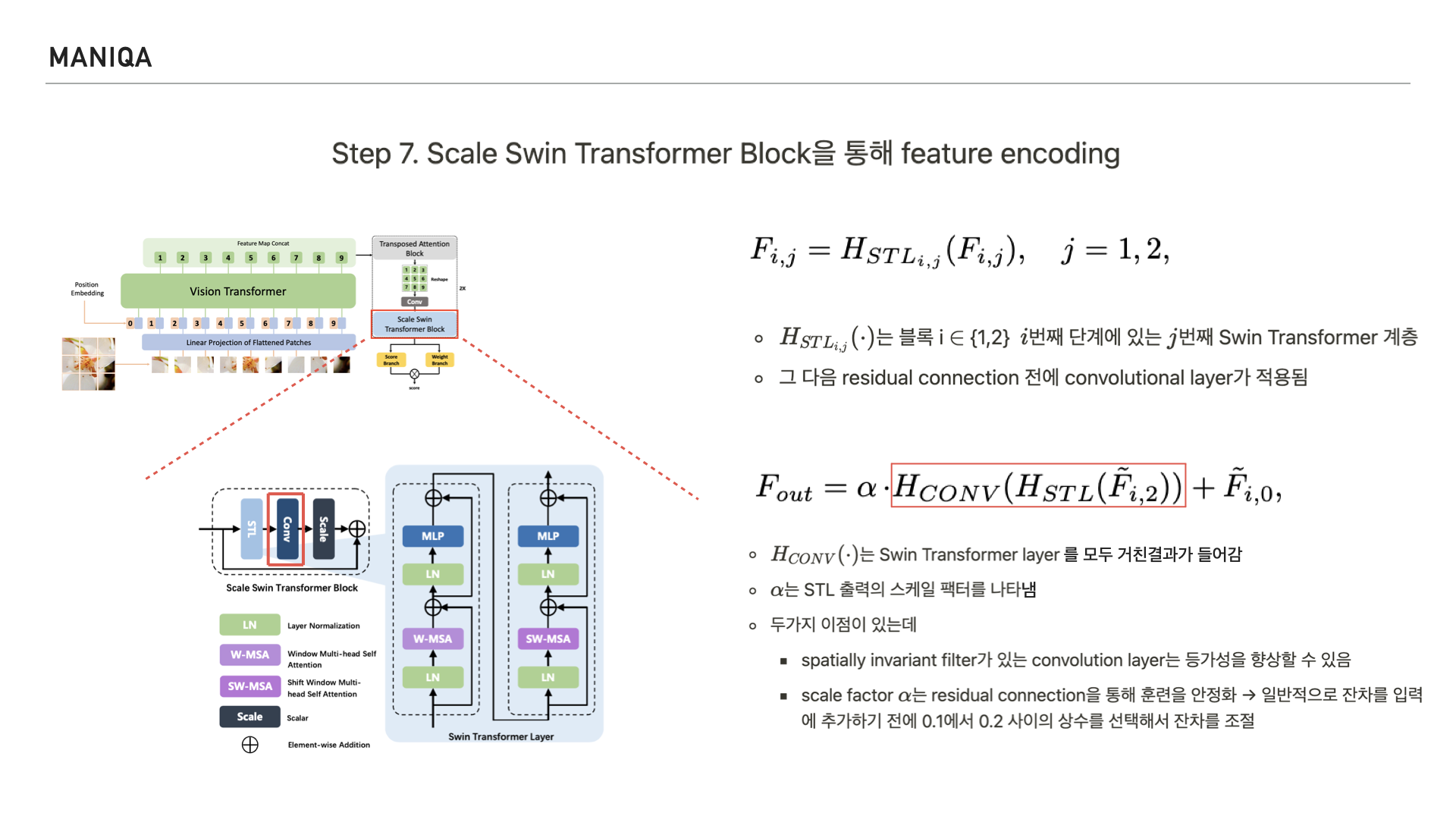
Convolution layer에는 앞서 Swin Transformer Layer를 거친 결과가 들어갑니다.
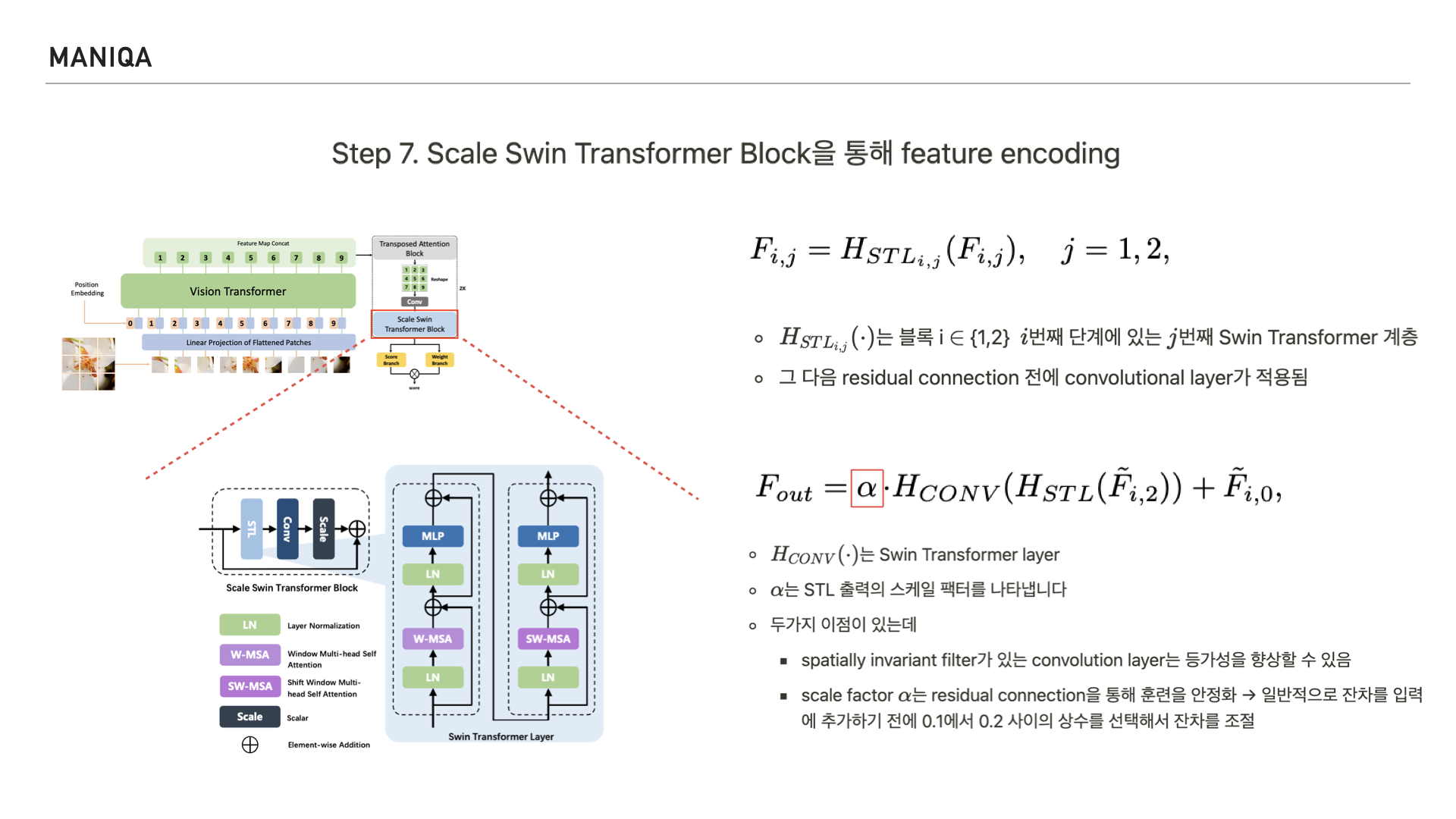
알파는 Swin Transformer Layer에서 나온 출력의 scale factor를 나타냅니다. 이런 구조를 취함으로써 두가지 이점을 얻게 되었는데, 하나는 convolution layer의 등가성(가치가 서로 같은 것을 요구하는 특성)을 향상시킬 수 있었다는 점과 또다른 하나는 이후 적용되는 residual connection을 통해 training 할 때 이를 안정화 시킬 수 있었다는 점입니다.
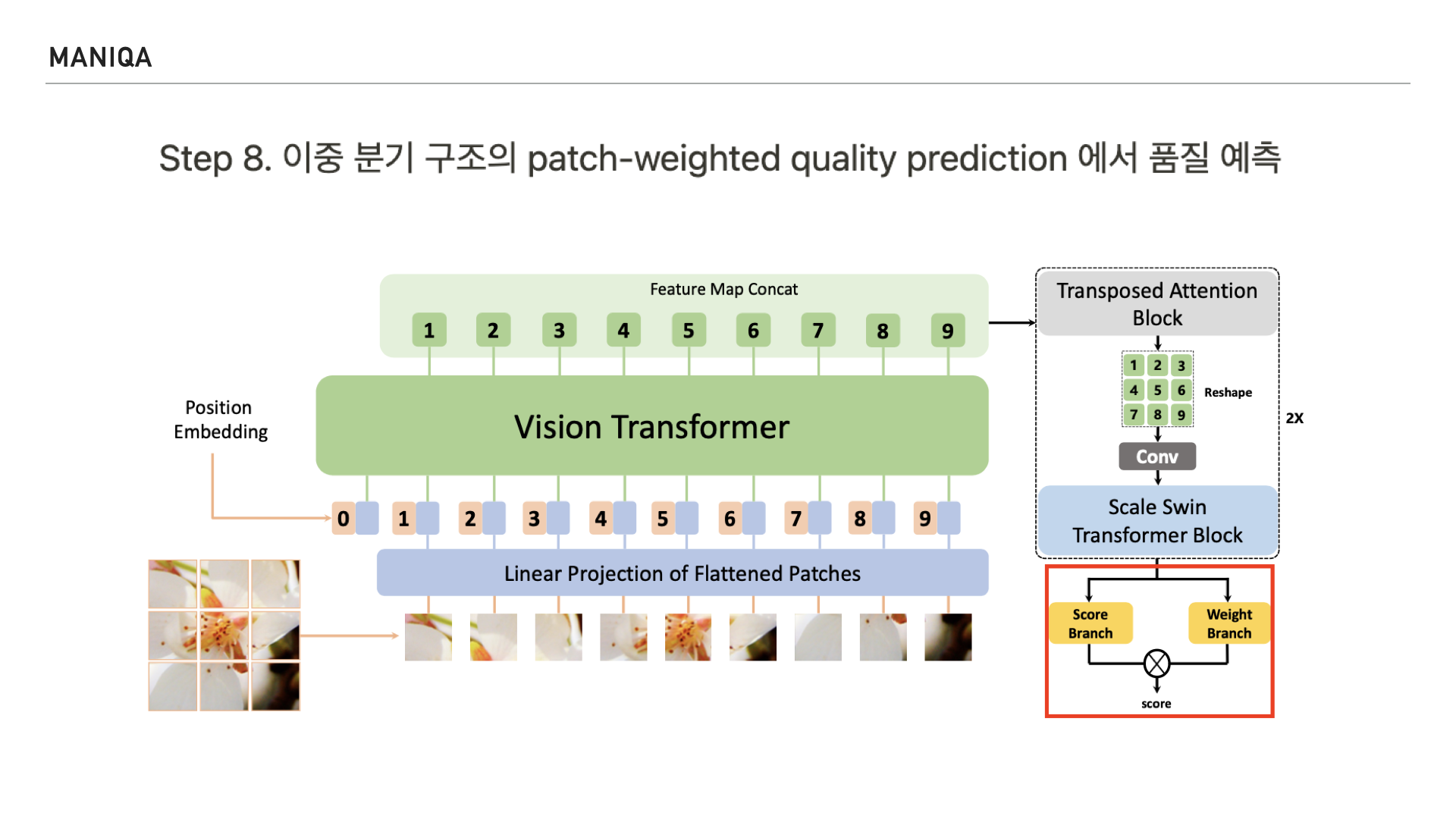
마지막으로 MANIQA에서는 이미지의 품질 예측 점수를 산출하는 Dual branch를 지나게 됩니다.
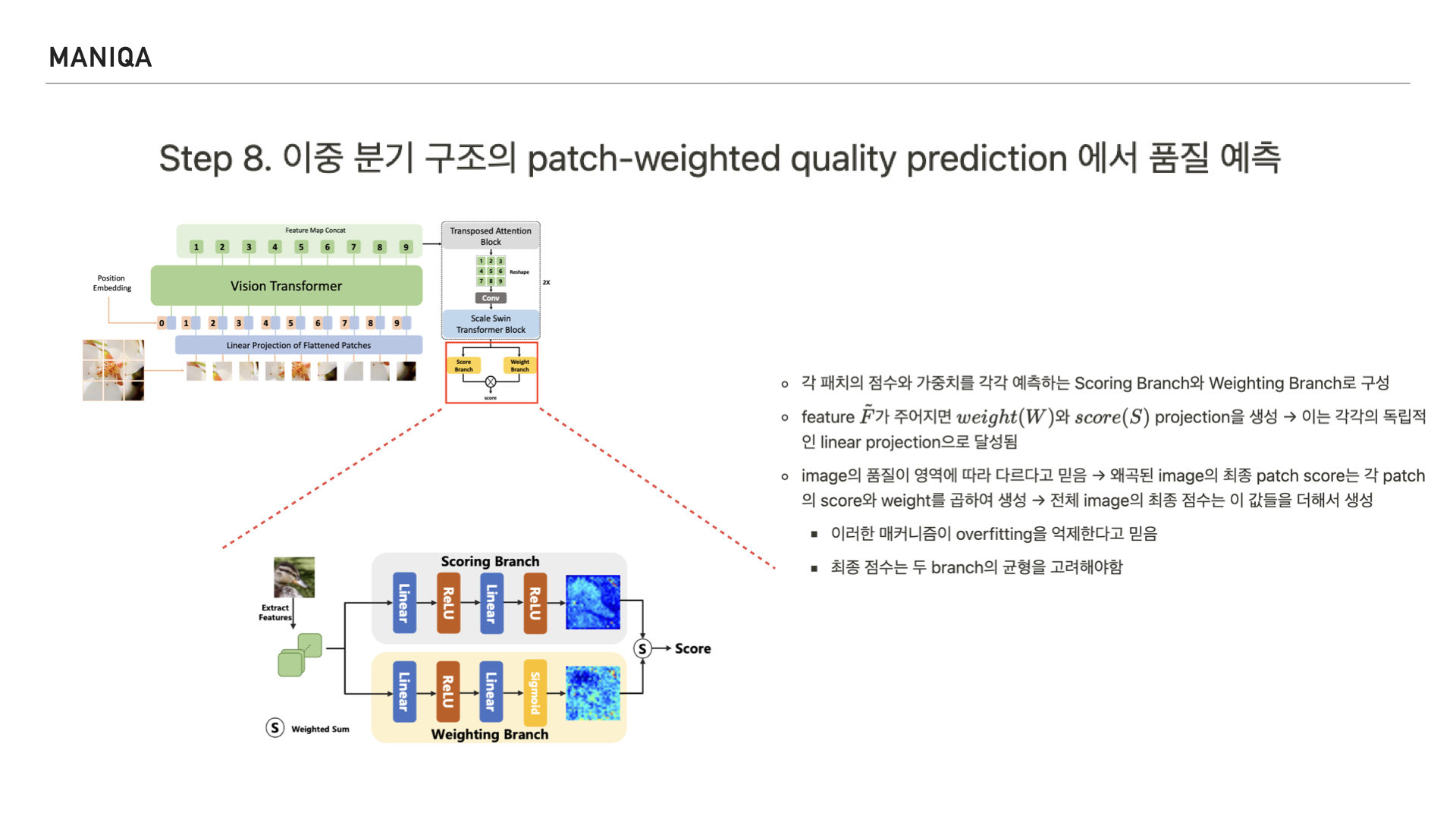
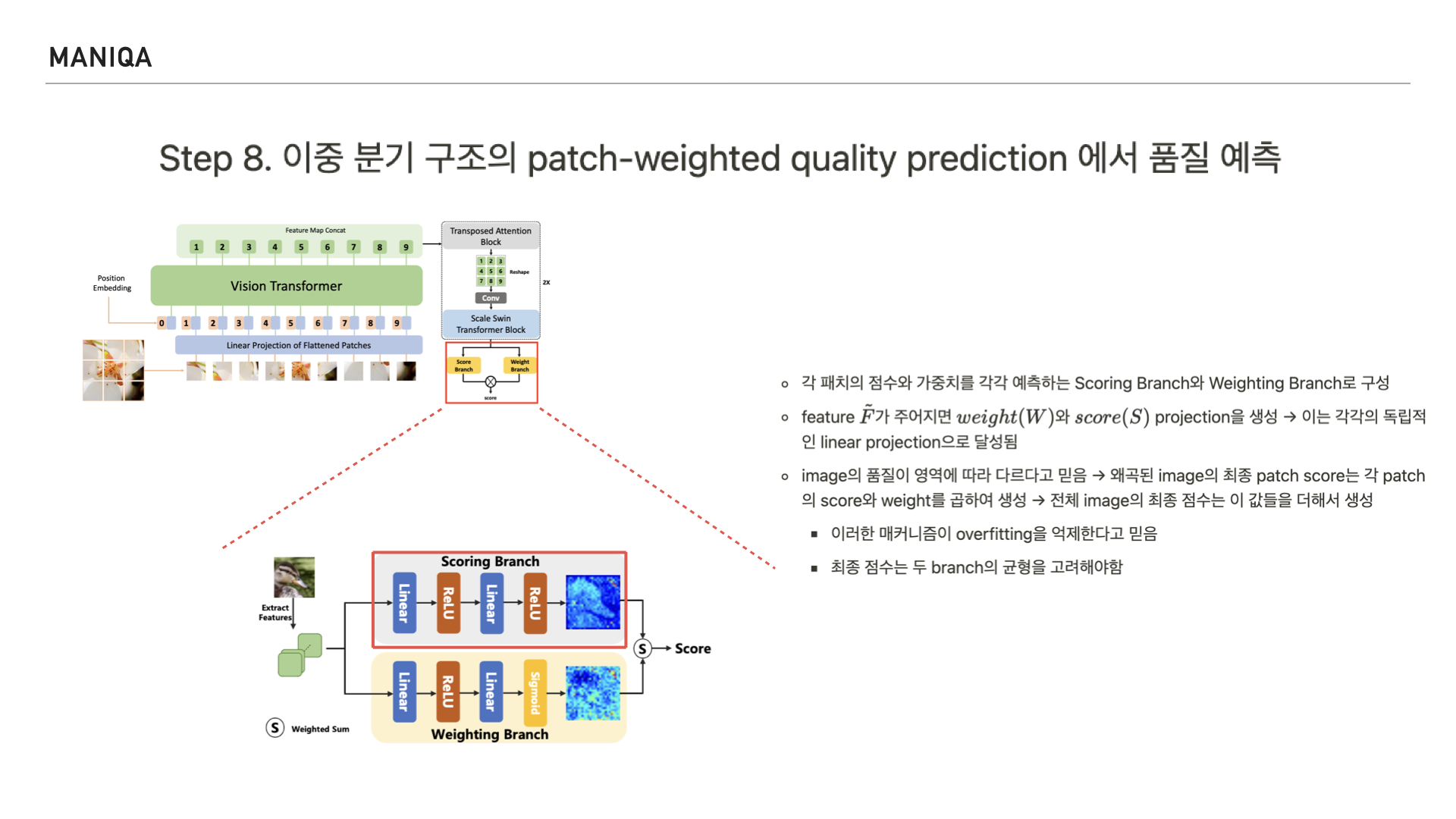
이 구조는 각 패치의 점수를 예측하는 scoring branch와
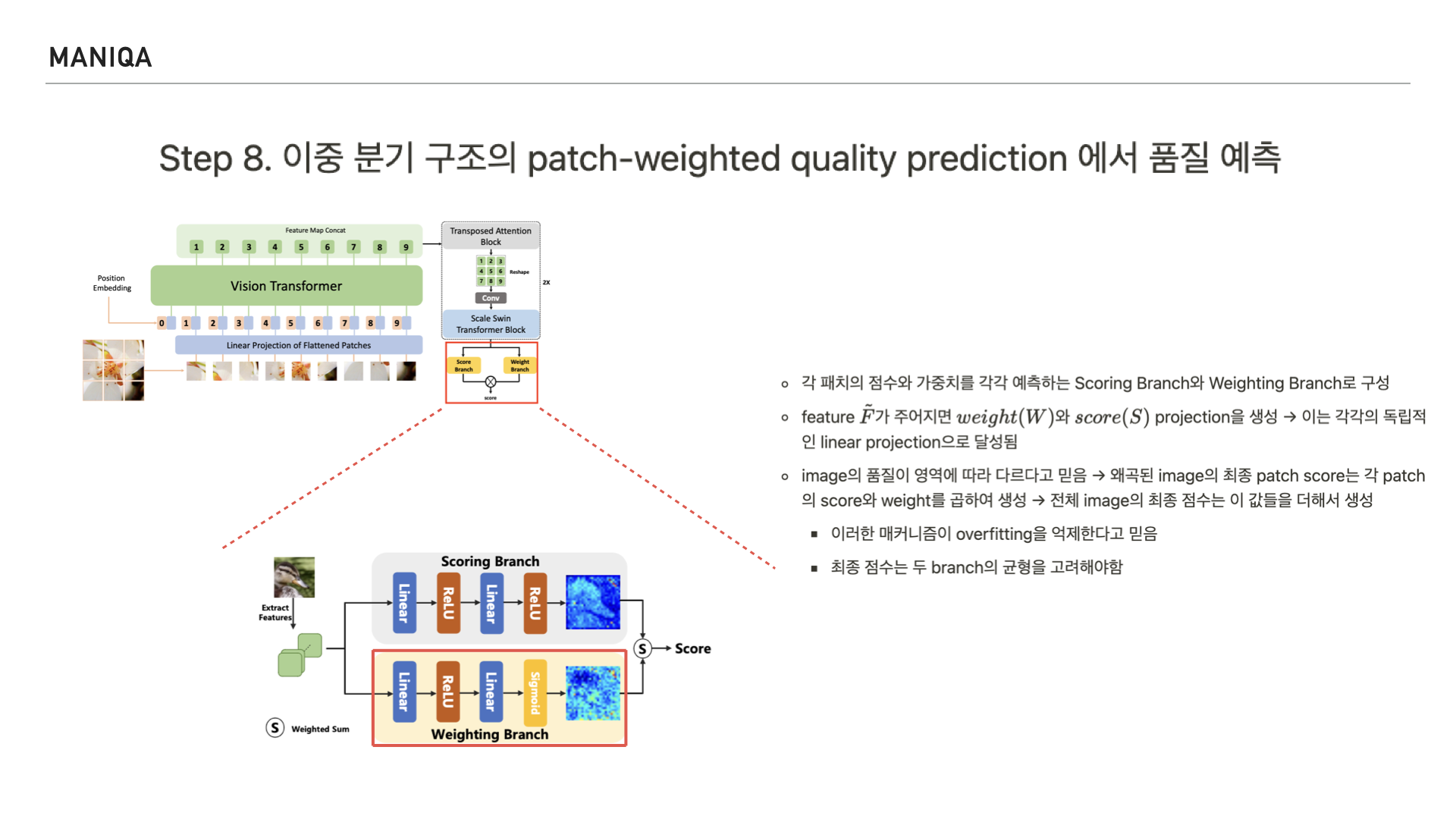
가중치를 예측하는 weighting branch로 이루어져 있으며 두 branch의 균형을 고려하여 점수를 매긴다고 합니다. 그리고 이를 통해 overfitting을 억제할 수 있다고 믿는다고 합니다.
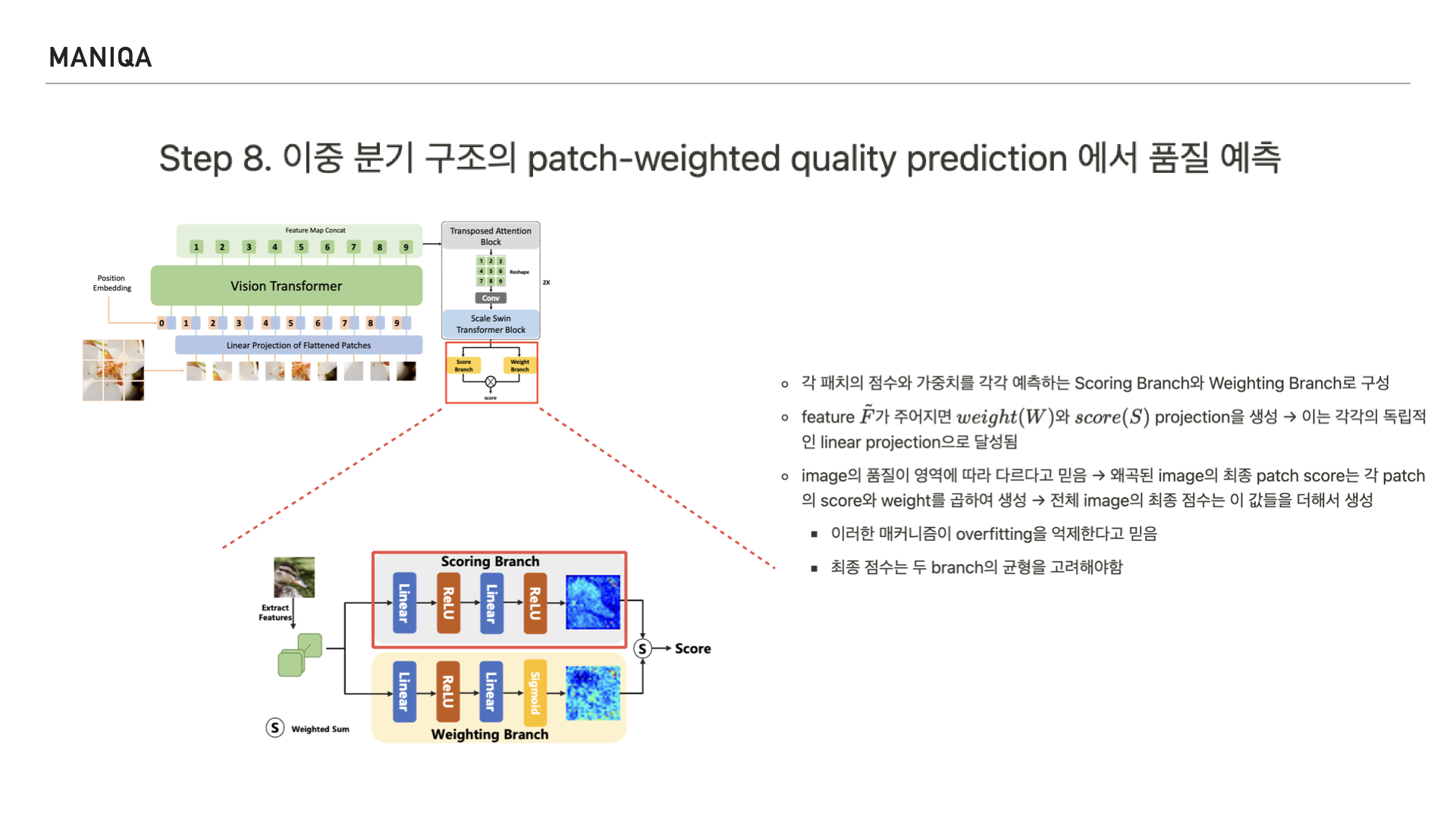
앞서 연계프로젝트 때 저와 저의 팀원들은 이미지의 feature에 대해 점수를 매기는 이 scoring branch에 FIQA 모델을 이식한 적이 있습니다.

다음은 모델의 훈련과 테스트에 사용된 데이터셋에 대한 간략한 정보와 코드상으로 구현되어있는 세부 정보에 대한 내용이 나와있습니다. 이부분은 이정도의 언급만 하고 넘어가도록 하겠습니다.


MANIQA는 원래 NTIRE 2022 Perceptual Image Quality Assessment Challenge Track 2: No-Reference에 참여하기 위한 모델이였는데요, 여기서는 왜곡된 이미지만을 input 받아 사용할 수 있습니다. 보시는 이미지는 NTIRE 2022 챌린지 검증 데이터셋에서의 예시 이미지 입니다.

왼쪽 이미지는 원본이미지이고 오른쪽은 왜곡된 이미지입니다. 각각 MOS와 예측점수가 기재되어 있으며, 괄호안의 숫자는 각 이미지의 품질 순위를 나타냅니다. 왜곡 이미지 아래의 이미지들은 patch weight map입니다. 보시는바와 같이 MOS에 근접한 품질 예측을 하고 있습니다.

다음으로 평가 기준에 대한 내용입니다. Pearson 상관계수는 ground-truth 점수와 예측 점수간의 선형성을 측정하는 지표이고 Spearman 상관계수는 ground-truth 점수와 예측 점수간의 단조성을 측정하는 지표입니다. 앞서 공분산에 대해 얘기를 했었는데 이 Pearson 상관계수가 표본 공분산으로 부터 나온 개념으로 볼 수 있습니다.
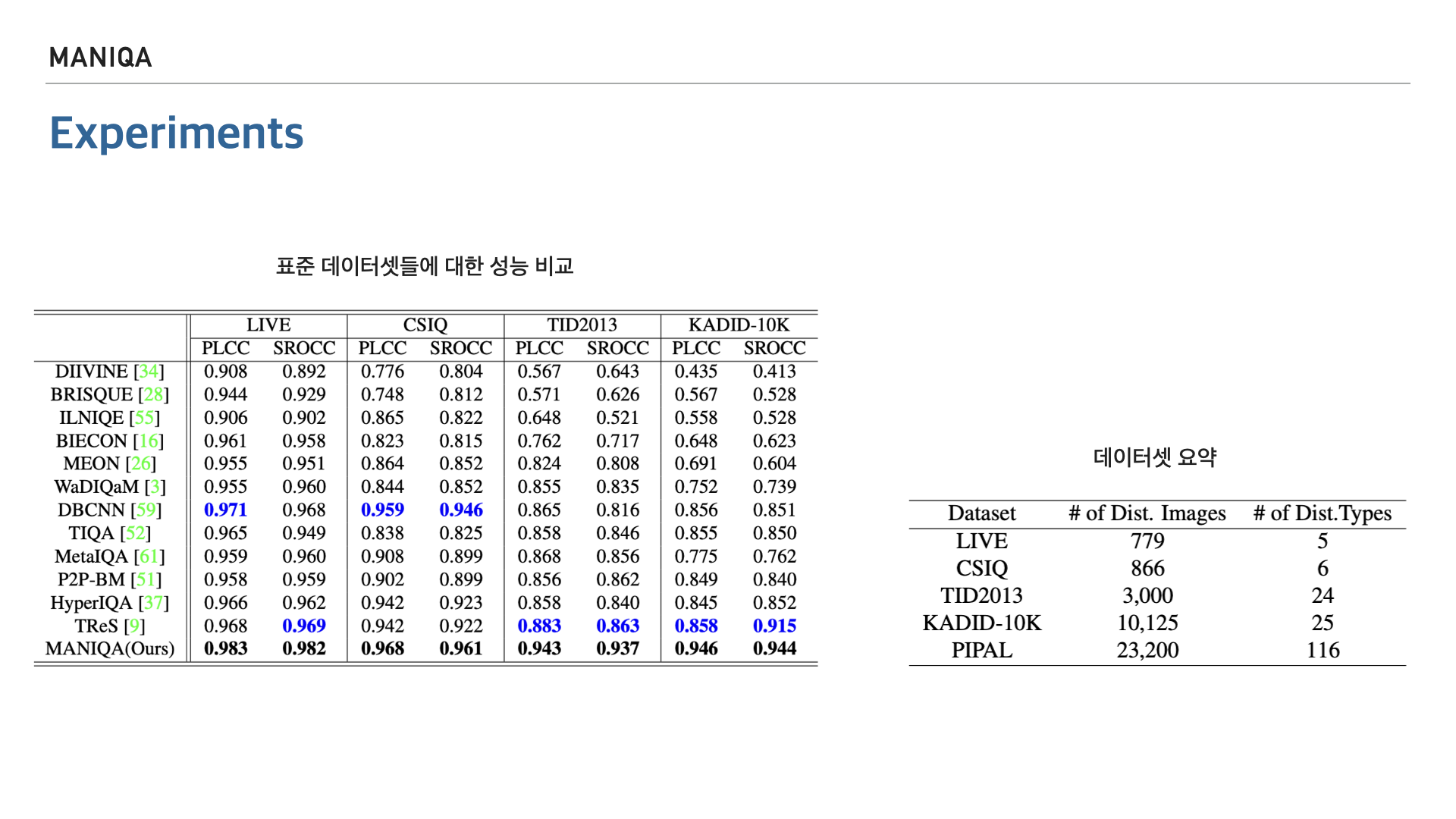
논문에서는 앞서 소개한 PLCC와 SROCC를 가지고 MANIQA를 다른 여러 알고리즘들과 비교하고 있습니다. 왼쪽의 표에서 파란색의 숫자는 MANIQA를 제외한 모델들 중 가장 높은 점수를 표시한 것이고 가장 아래에 있는 굵은 숫자가 현재 저희가 살펴보고 있는 MANIQA의 점수입니다. 보시는바와 같이 전부 가장 높은 점수를 차지한것을 알 수 있습니다. 오른쪽 표는 각 데이터셋에 대한 요약입니다.
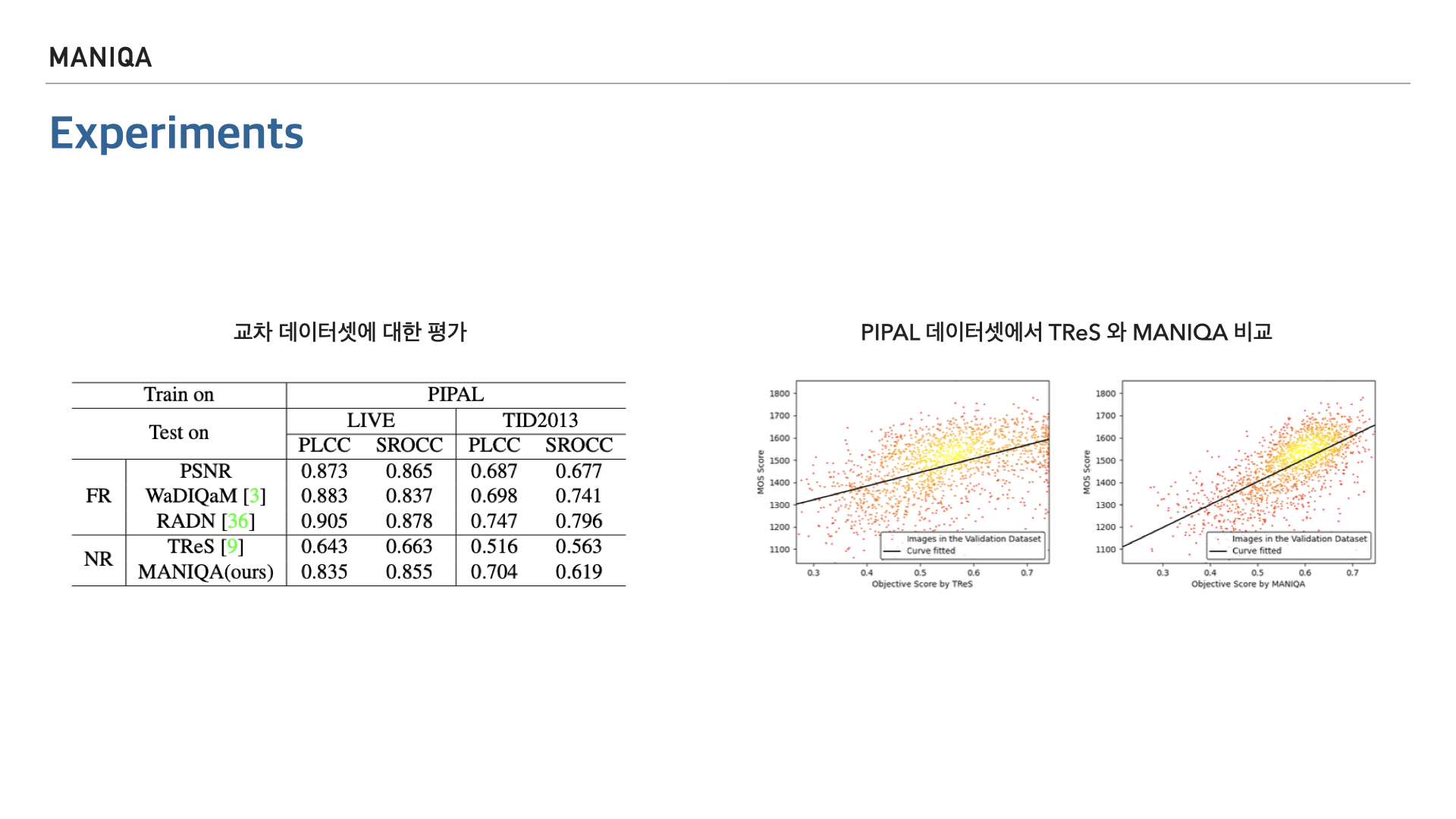
다음은 FR방식의 모델과 NR방식의 모델을 PIPAL 데이터셋으로 train하여 두가지 표준 데이터셋을 평가해 본 결과입니다. FR방식에 비해 나은 점도 없고 못한 점도 없다고 보여집니다. 오른쪽은 같은 NR 방식의 모델인 TReS와의 비교입니다. PIPAL 데이터셋에서 실험을 하였고 표의 가로축은 예측 점수를, 세로축은 MOS 점수를 나타냅니다. 산점도로 표현이 되어있는데 왼쪽이 TReS, 오른쪽이 MANIQA 입니다. 점이 분포한 영역의 넓이와 기울기로 보았을 때 MANIQA가 더 높은 성능을 보인다고 할 수 있습니다.
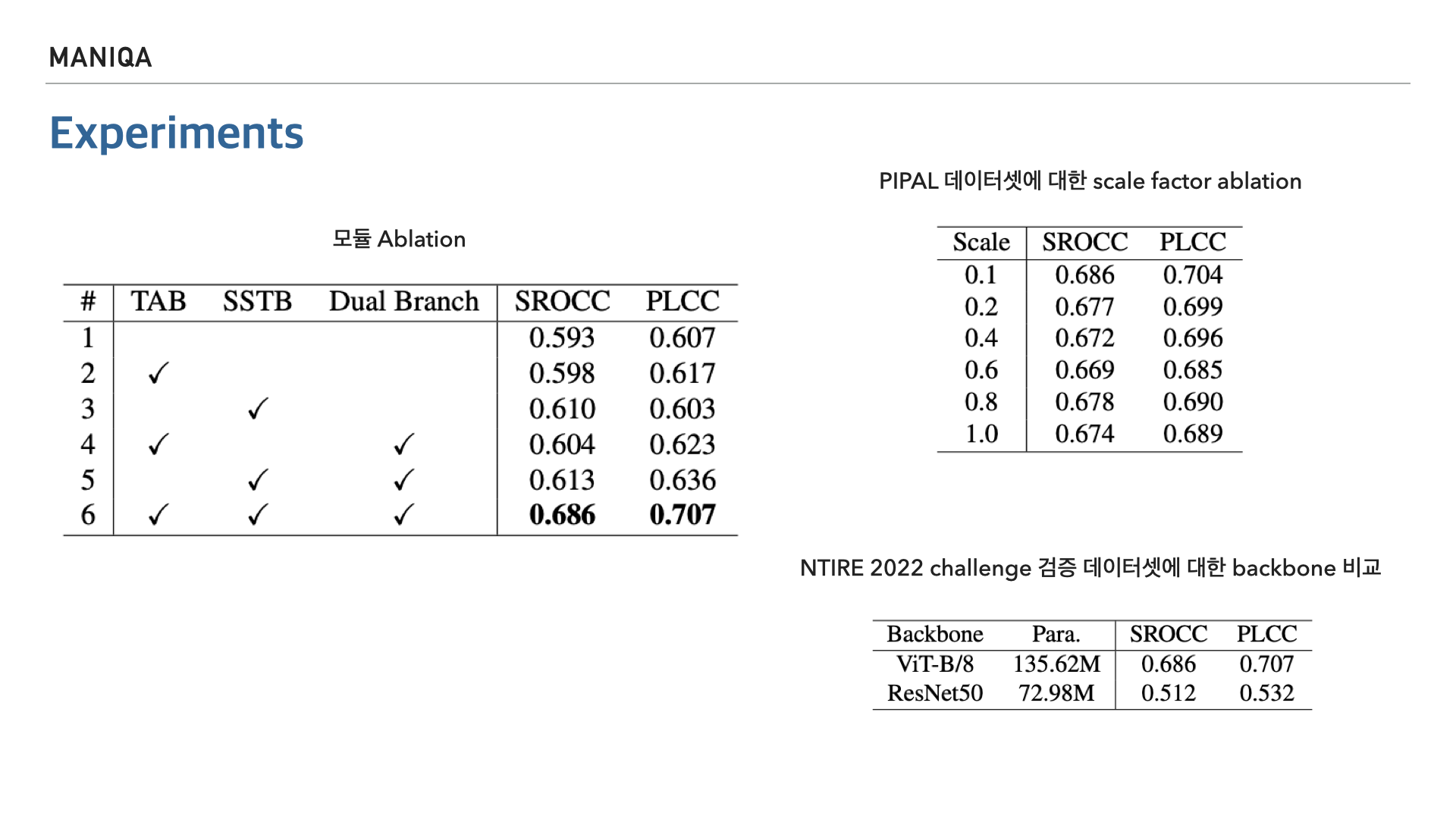
다음은 모듈에 대한 절제 연구 결과입니다. 해당 논문에서 제시한 Transposed Attention Block, Scale Swin Transformer Block, Dual Branch에 대해 사용했을 때와 사용하지 않았을 때의 지표 점수를 정리했습니다. 결과적으로 제안한 모듈을 모두 사용했을 때 가장 좋은 성능을 보여주었습니다. 오른쪽 위 표는 PIPAL 데이터셋에 대한 scale factor 실험 결과이고 오른쪽 아래 표는 backbone을 resnet으로 사용했을 때와의 비교입니다.(para -> 모델의 매개변수)
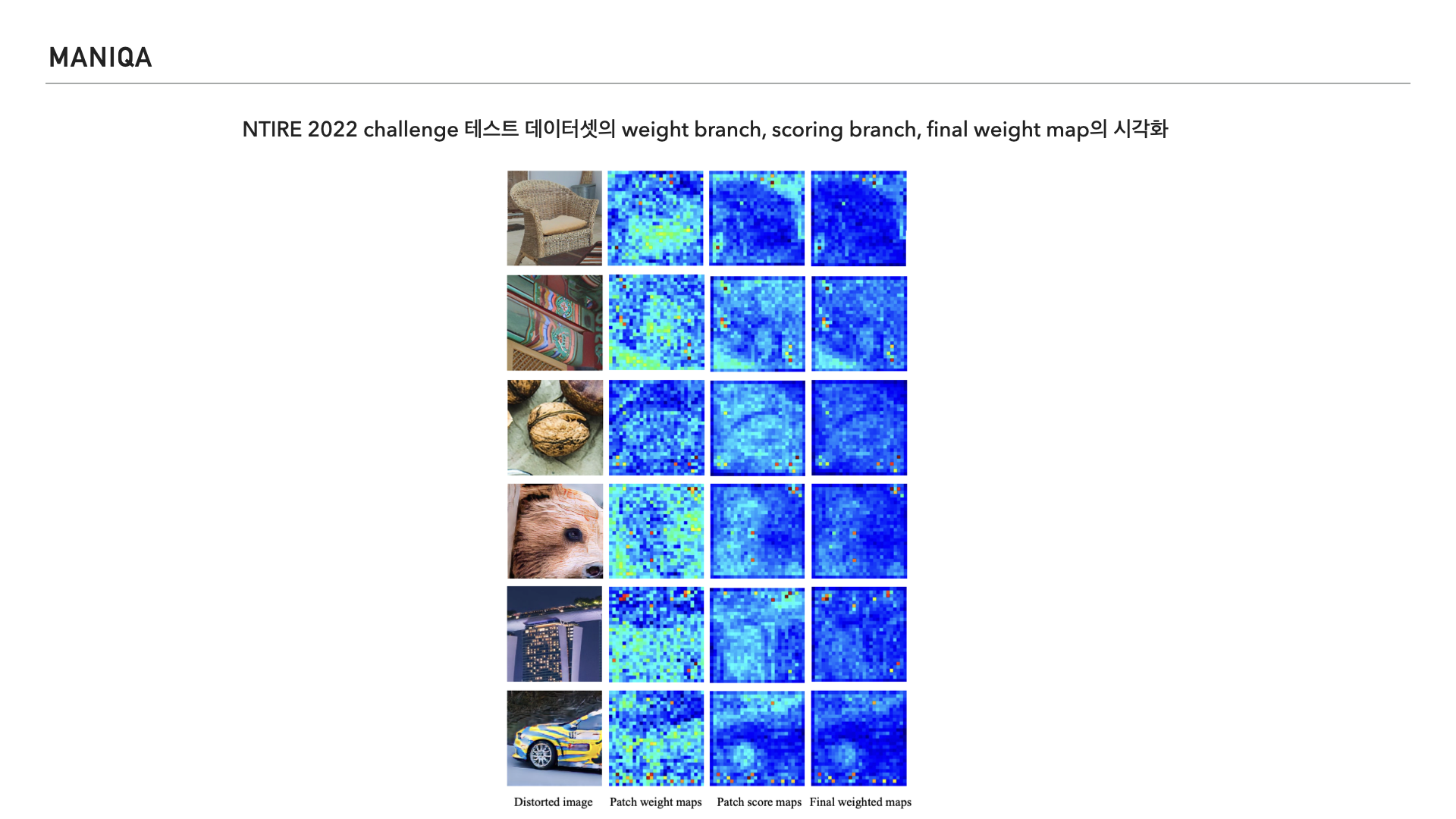
마지막으로 NTIRE 2022 challenge 테스트 데이터셋에 대해 weight branch, scoring branch, final weight map을 시각화 하여 보여주고 있습니다. 왜곡된 이미지에 대한 평가를 할 때 모델이 의도한대로 잘 작동한다는걸 보여주려고 한 것 같습니다.

결론입니다. 논문에서는 앞선 과정을 통해 이미지 지각 품질 평가에 다차원적인 상호작용이 꼭 필요하다는 걸 확인했다고 합니다. 또한 GAN기반의 왜곡 중 비현실적이지만 만족스럽게 생성된 질감이나 만족스럽지 못한 질감에 대해 잘 정의하는 것이 이런 Task를 개선하기 위해 중요하다고 합니다.

논문을 리뷰하며 느낀 점
그동안 깊은 이해나 고찰, 연구 없이 그런가보다 하고 넘어가던 부분들이 결국엔 깊은 이해와 고찰, 연구가 필요한 부분이였고 인공지능 개발자라는 포지션은 논문을 구현하는 코딩실력 뿐만 아니라 논문에 대해 이해하고 연구하고 응용하는 연구직의 성격이 강하다는 것을 알게되었습니다.
댓글남기기